Go channel 的妙用
昨天在内网上看到一篇讲数据库连接的文章,列出了一些 sql 包的一些源码,我注意到其中取用、归还连接的方式非常有意思——通过临时创建的 channel 来传递连接。
在 sql.DB 结构体里,使用 freeConn 字段来表示当前所有的连接,也就是一个连接池。
当需要拿连接的时候,从 freeConn 中取出第一个元素:
1conn := db.freeConn[0]
2copy(db.freeConn, db.freeConn[1:])
3db.freeConn = db.freeConn[:numFree-1]
4conn.inUse = true
取 slice 切片的第一个元素,然后将 slice 后面的元素往前挪,最后通过截断来“释放”最后一个元素。
当然,能进行上述操作的前提是切片 db.freeConn 长度大于 0,即有空闲连接存在。如果当前没有空闲连接,那如何处理呢?接下来就是 channel 的妙用的地方。
sql.DB 结构体里还有另一个字段 connRequests,它用来存储当前有哪些“协程”在申请连接:
connRequests 的 key 是一个 uint64类型,其实就是一个递增加 1 的 key;而 connRequest 表示申请一个新连接的请求:
这里的 conn 正是需要的连接。
当连接池中没有空闲连接的时候:
1req := make(chan connRequest, 1)
2reqKey := db.nextRequestKeyLocked()
3db.connRequests[reqKey] = req
先是构建了一个 chan connRequest,同时拿到了一个 reqKey,将它和 req 绑定到 connRequests 中。
接下来,在 select 中等待超时或者从 req 这个 channel 中拿到空闲连接:
1select {
2 case <-ctx.Done():
3
4 case ret, ok := <-req:
5 if !ok {
6 return nil, errDBClosed
7 }
8
9 return ret.conn, ret.err
10}
可以看到,select 有两个 case,第一个是通过 context 控制的 <-Done;第二个则是前面构造的 <-req,如果从 req 中读出了元素,那就相当于获得了连接:ret.conn。
那什么时候会向 req 中发送连接呢?答案是在向连接池归还连接的时候。
前面提到,空闲连接是一个切片,归还的时候直接 append 到这个切片就可以了:
1func (db *DB) putConnDBLocked(dc *driverConn, err error) bool {
2 db.freeConn = append(db.freeConn, dc)
3}
但其实在 append 之前,还会去检查当前 connRequests 中是否有申请空闲连接的请求:
1if c := len(db.connRequests); c > 0 {
2 var req chan connRequest
3 var reqKey uint64
4 for reqKey, req = range db.connRequests {
5 break
6 }
7 delete(db.connRequests, reqKey) // Remove from pending requests.
8 if err == nil {
9 dc.inUse = true
10 }
11 req <- connRequest{
12 conn: dc,
13 err: err,
14 }
15 return true
16}
如果有请求的话,直接将当前连接“塞到” req channel 里去了。另一边,申请连接的 goroutine 就可以从 req channel 中读出 conn。
于是,通过 channel 就实现了一次“连接传输”的功能。
这让我想到不久之前芮神写的一篇《高并发服务遇redis瓶颈引发time-wait事故》,文中提到了将多个 redis command 组装为一个 pipeline:
调用方把 redis command 和接收结果的 chan 推送到任务队列中,然后由一个 worker 去消费,worker 组装多个 redis cmd 为 pipeline,向 redis 发起请求并拿回结果,拆解结果集后,给每个命令对应的结果 chan 推送结果。调用方在推送任务到队列后,就一直监听传输结果的 chan。
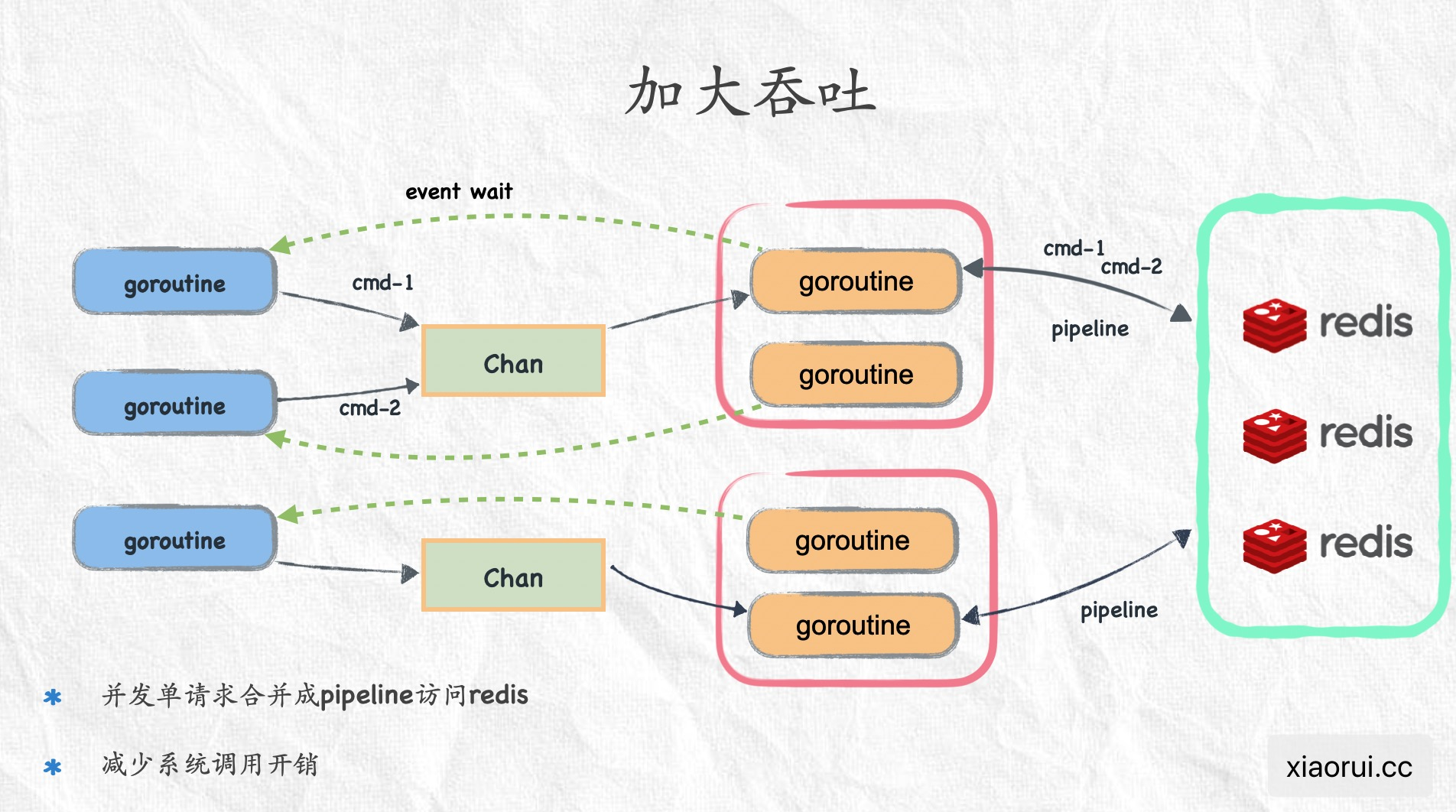
这里的用法就和本文描述的 channel 用法一致。
细想一下,以上提到的 channel 用法很神奇吗?我们平时没有接触过吗?
我用过最多的是“生产者-消费者”模式,先启动 N 个 goroutine 消费者,读某个 channel,之后,生产者再在某个时候向 channel 中发送元素:
1for i := 0; i < engine.workerNum; i++ {
2 go func() {
3 for {
4 work = <-engine.workChan
5 }
6 }
7}
另外,我还会用 channel 充当一个 “ready” 的信号,用来指示某个“过程”准备好了,可以接收结果了:
前面提到的“生产者-消费者”和 “ready” 信号这两种 channel 用法和本文的 channel 用法并没有什么本质区别。唯一不同的点是前者的 channel 是事先创建好的,并且是“公用”的;而本文中用到的 channel 实际上是“临时”创建的,并且只有这一个请求使用。
最后,用曹大最近在读者群里说的话结尾:
抄代码是很好的学习方式。
选一两个感兴趣的方向,自己尝试实现相应的 feature list,实现完和标准实现做对比。
先积累再创造,别一上来就想着造轮子,看的多了碰上很多东西就有新思路了。
- 原文作者:饶全成
- 原文链接:https://qcrao.com/post/ingenious-use-of-channel/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
