写一个 panic blame 机器人
最近接手了一个“公共”服务,负责维护它的稳定性。代码库有很多人参与“维护”,其实就是各种业务方使劲往上堆逻辑。虽然入库前我会进行 CR,但多了之后,也看不过来,还有一些人自己偷摸就把代码合到 master 上去了。总之,代码质量无法得到很好的保证。
当然了,如果把合代码的权限收敛到我一个人,理论上是可行的。但是,一方面,业务迭代的速度很可能就 block 在我这了;另一方面,业务方的迭代逻辑涉及很多具体的业务,我也不太熟。所以,CR 的时候也只能看一些诸如 go 出去的 func 有没有加 recover、有没有异常使用空指针等等,对于业务相关的代码提不出什么有用的意见。
其实有一些业务方的逻辑和其他业务方完全独立(使用的接口和其他业务方独立),后续会将当前的服务完全“复制”一份出来,交给业务方自行维护。
但眼下有一个问题需要解决:报警群里时不时来一个 recovered panic 的报警,我看到报警后就要登上机器看日志,执行 “grep -C 10 panic xxx.log” 这样的命令看 panic 发生在哪里。再执行 git blame 看看究竟是谁写的,再去群里 @ 他进行处理。但很多情况下是这些 panic 是由脏数据导致的,发生的也不频繁,并且 panic 被 recover 住了,所以也不太着急。
问题是业务方写完了代码之后,基本也不太关心服务运行地怎么样,但作为服务负责人得管。像前面提到的 panic 报警发生的多了,我“查日志,定位到代码提交人再通知他处理”的事情多了之后,就想能不能写一个 panic blame 机器人来做这件事。这样就能省不少事,而且还显得那么优雅。
想好了要做这件事,其实也并不困难。
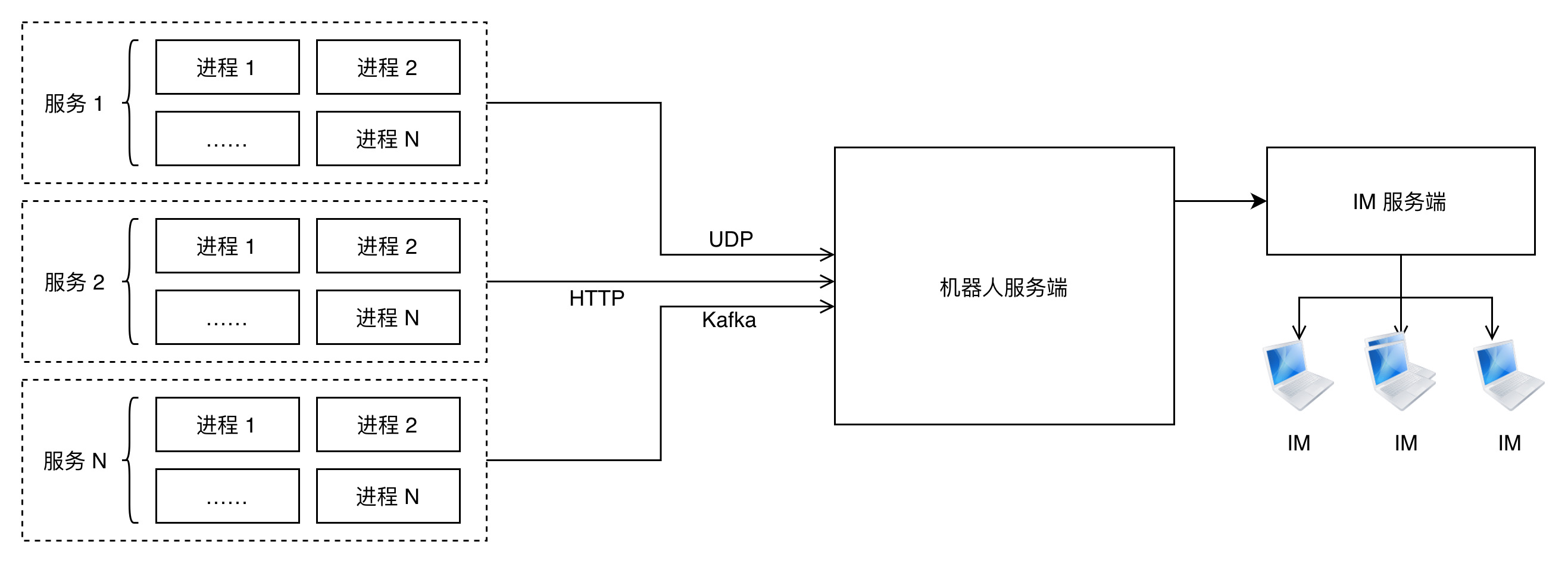
最朴素的思路就是在 recover 函数里把 panic 发生时的一些信息,例如 pod-name、机器 ip、服务名、stack 等通过 HTTP 请求发送到某个服务,这个服务收到 stack 后分析出 panic 的那行代码,再请求 git 服务的某个接口,拿到提交人及提交时间。整体如下:
我们再看看具体代码是怎么写的。例如,Recover 函数是这样的:
1func RecoverFromPanic(funcName string) {
2 if e := recover(); e != nil {
3 buf := make([]byte, 64<<10)
4 buf = buf[:runtime.Stack(buf, false)]
5
6 logs.Errorf("[%s] func_name: %v, stack: %s", funcName, e, string(buf))
7
8 panicError := fmt.Errorf("%v", e)
9 panic_reporter_client.ReportPanic(panicError.Error(), funcName, string(buf))
10 }
11
12 return
13}
向机器人服务端发送 panic 信息的 panic_reporter_client 代码:
1const url = "http://localhost:8888/report-panic"
2
3// 为了避免造成 panic report 服务被打挂,降低发送 http 请求频率,进程生命周期内只发一次
4var panicReportOnce sync.Once
5
6type PanicReq struct {
7 Service string `json:"service"`
8 ErrorInfo string `json:"error_info"`
9 Stack string `json:"stack"`
10 LogId string `json:"log_id"`
11 FuncName string `json:"func_name"`
12 Host string `json:"host"`
13 PodName string `json:"pod_name"`
14}
15
16func ReportPanic(errInfo, funcName, stack string) (err error) {
17 panicReportOnce.Do(func() {
18 defer func() {recover()}()
19
20 go func() {
21 panicReq := &PanicReq {
22 Service: env.Service(),
23 ErrorInfo: errInfo,
24 Stack: stack,
25 FuncName: funcName,
26 Host: env.HostIP(),
27 PodName: env.PodName(),
28 }
29
30 var jsonBytes []byte
31 jsonBytes, err = json.Marshal(panicReq)
32 if err != nil {
33 return
34 }
35
36 var req *http.Request
37 req, err = http.NewRequest("GET", url, bytes.NewBuffer(jsonBytes))
38 if err != nil {
39 return
40 }
41 req.Header.Set("Content-Type", "application/json")
42
43 client := &http.Client{Timeout: 5 * time.Second}
44 var resp *http.Response
45 resp, err = client.Do(req)
46 if err != nil {
47 return
48 }
49 defer resp.Body.Close()
50
51 return
52 }()
53 })
54
55 return
56}
解析出 panic 消息的代码也不难,我们需要看一下如何从 stack 信息中找到 panic 的那一行。
举一个例子来说明:
1package main
2
3import (
4 "fmt"
5 "runtime"
6)
7
8func a() {
9 fmt.Println("a")
10 b()
11}
12
13func b() {
14 fmt.Println("b")
15 c()
16}
17
18type Student struct {
19 Name int
20}
21
22func c() {
23 defer RecoverFromPanic("fun c")
24 fmt.Println("c")
25 var a *Student
26 fmt.Println(a.Name)
27}
28
29func main() {
30 a()
31}
32
33func RecoverFromPanic(funcName string) {
34 if e := recover(); e != nil {
35 buf := make([]byte, 64<<10)
36 buf = buf[:runtime.Stack(buf, false)]
37
38 fmt.Printf("[%s] func_name: %v, stack: %s", funcName, e, string(buf))
39 }
40
41 return
42}
这是一个有几层调用关系的例子,假装我们年幼无知直接解引用了一个空指针,导致 panic,但被 recover 了,输出的调用栈信息如下:
1goroutine 1 [running]:
2main.RecoverFromPanic(0x4c4551, 0x5)
3 /home/raoquancheng/go/src/hello/test.go:36 +0xb5
4panic(0x4a9340, 0x55b8d0)
5 /usr/local/go/src/runtime/panic.go:679 +0x1b2
6main.c()
7 /home/raoquancheng/go/src/hello/test.go:26 +0xd4
8main.b()
9 /home/raoquancheng/go/src/hello/test.go:15 +0x7a
10main.a()
11 /home/raoquancheng/go/src/hello/test.go:10 +0x7a
12main.main()
13 /home/raoquancheng/go/src/hello/test.go:30 +0x20
栈信息中,首先是 runtime.Stack 函数那一行;接着是 /usr/local/go/src/runtime/panic.go:679,也就是 runtime 里的 gopanic 函数;下一行就是真正引起 panic 的使用空指针的那一行代码,这是罪魁祸首,panic blame 机器人主要关注这个;之后的信息就是调用链关系,会一直追溯到 main 函数里调用 a() 的源头。
分析出来这些信息后,向 IM 提供的机器人 webhook 地址发送 panic 消息,并顺带 @ 刚才找到的代码提交人,老哥,你又写出 panic 了:
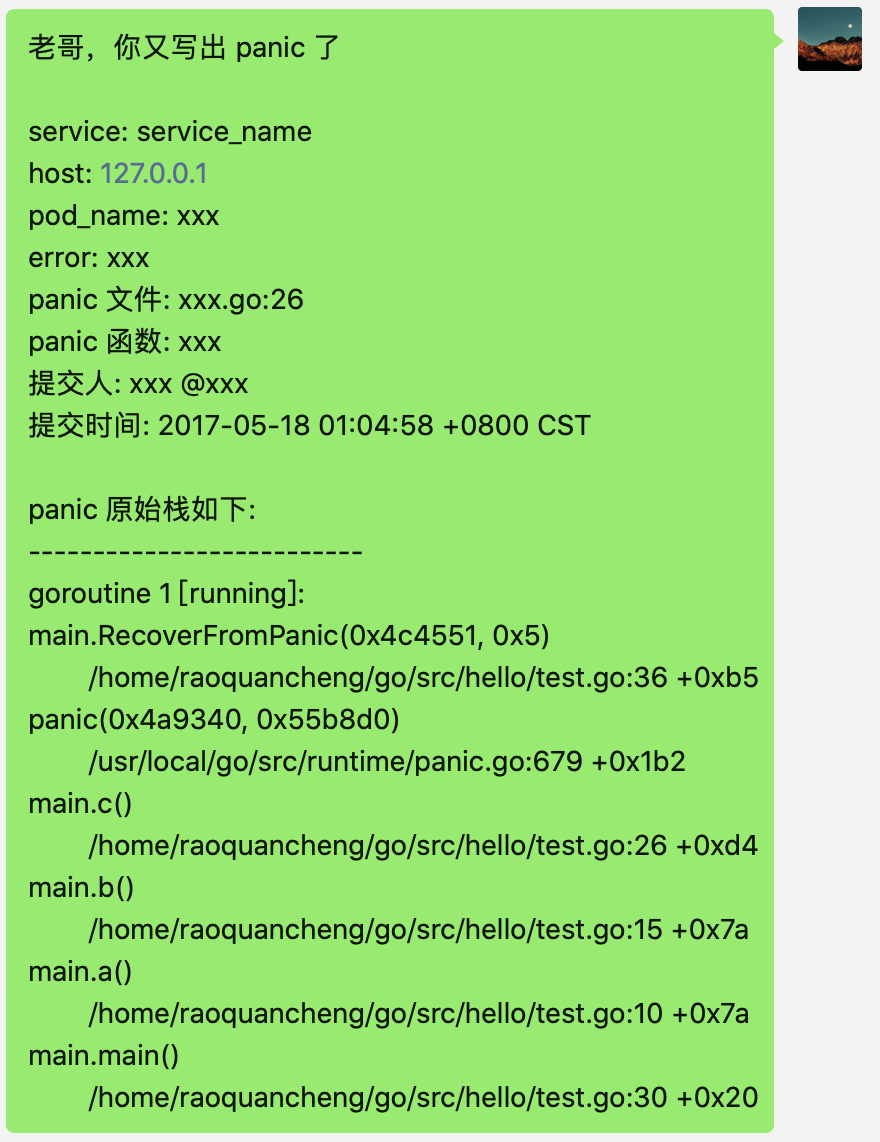
这样是不是就是万事大吉了?
并不是,还有一些关键问题需要考虑。首先业务进程不能阻塞在发送 panic 信息的过程中,且发送 panic 信息的代码不能再发次发生 panic,以免给业务进程带来二次伤害。这样就需要以异步的方式发送消息,并且最好是通过消息队列或者 UDP 这种“我发完了就不管了”的姿态发送。
机器人服务端用生产者消费者的形式来解析业务进程发送上来的消息。无论业务进程是以 HTTP,还是 UDP 或者消息队列发过来的 panic 报告请求最终都要进入一个“池子”,HTTP、UDP、消息队列也就是所谓的生产者,消费者协程则从“池子”里取出 panic 报告请求,解析、发送报警@人处理。
还有一个需要考虑的是机器人服务端不要被打跨了,尤其是考虑到一些业务跑在几千个实例上的时候,更要注意了。
分别从客户端和服务端两方面来看。
对于客户端,在一个进程生命周期内,同时发生多“种” panic 的情况并不多见,因此我们只需要在进程生命周期内发送一次就行了,用 sync.Once。
在服务端,对同一个业务发送的请求进行限流和聚合,例如每秒只处理同一个业务的一个请求,对被限流的请求做聚合,报告一个总的 panic 数量就行了。
另一个可能需要考虑的是如果 panic 代码提交者离职了怎么办?或者说我只是做了一下 format,真实的提交者并不是我,怎么办?
我们并不能做到 100% 的准确,现实有很多的边角没法解决。比如代码提交者并没有离职,但他转岗了……有个可以考虑的方法是看 panic 那一行代码附近的最近修改过代码的人是谁,找他,或者直接找服务负责人好了。不求完美,只要能解决大部分问题就行了。
实现一个 panic blame 机器人比较简单,但考虑服务稳定性的话,还是有一些点要注意的。
- 原文作者:饶全成
- 原文链接:https://qcrao.com/post/panic-blame-robot/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
