深度解密 Go 语言之 sync.map
工作中,经常会碰到并发读写 map 而造成 panic 的情况,为什么在并发读写的时候,会 panic 呢?因为在并发读写的情况下,map 里的数据会被写乱,之后就是 Garbage in, garbage out,还不如直接 panic 了。
是什么
Go 语言原生 map 并不是线程安全的,对它进行并发读写操作的时候,需要加锁。而 sync.map 则是一种并发安全的 map,在 Go 1.9 引入。
sync.map是线程安全的,读取,插入,删除也都保持着常数级的时间复杂度。
sync.map的零值是有效的,并且零值是一个空的 map。在第一次使用之后,不允许被拷贝。
有什么用
一般情况下解决并发读写 map 的思路是加一把大锁,或者把一个 map 分成若干个小 map,对 key 进行哈希,只操作相应的小 map。前者锁的粒度比较大,影响效率;后者实现起来比较复杂,容易出错。
而使用 sync.map 之后,对 map 的读写,不需要加锁。并且它通过空间换时间的方式,使用 read 和 dirty 两个 map 来进行读写分离,降低锁时间来提高效率。
如何使用
使用非常简单,和普通 map 相比,仅遍历的方式略有区别:
1package main
2
3import (
4 "fmt"
5 "sync"
6)
7
8func main() {
9 var m sync.Map
10 // 1. 写入
11 m.Store("qcrao", 18)
12 m.Store("stefno", 20)
13
14 // 2. 读取
15 age, _ := m.Load("qcrao")
16 fmt.Println(age.(int))
17
18 // 3. 遍历
19 m.Range(func(key, value interface{}) bool {
20 name := key.(string)
21 age := value.(int)
22 fmt.Println(name, age)
23 return true
24 })
25
26 // 4. 删除
27 m.Delete("qcrao")
28 age, ok := m.Load("qcrao")
29 fmt.Println(age, ok)
30
31 // 5. 读取或写入
32 m.LoadOrStore("stefno", 100)
33 age, _ = m.Load("stefno")
34 fmt.Println(age)
35}
第 1 步,写入两个 k-v 对;
第 2 步,使用 Load 方法读取其中的一个 key;
第 3 步,遍历所有的 k-v 对,并打印出来;
第 4 步,删除其中的一个 key,再读这个 key,得到的就是 nil;
第 5 步,使用 LoadOrStore,尝试读取或写入 “Stefno”,因为这个 key 已经存在,因此写入不成功,并且读出原值。
程序输出:
sync.map 适用于读多写少的场景。对于写多的场景,会导致 read map 缓存失效,需要加锁,导致冲突变多;而且由于未命中 read map 次数过多,导致 dirty map 提升为 read map,这是一个 O(N) 的操作,会进一步降低性能。
源码分析
数据结构
先来看下 map 的数据结构。去掉大段的注释后:
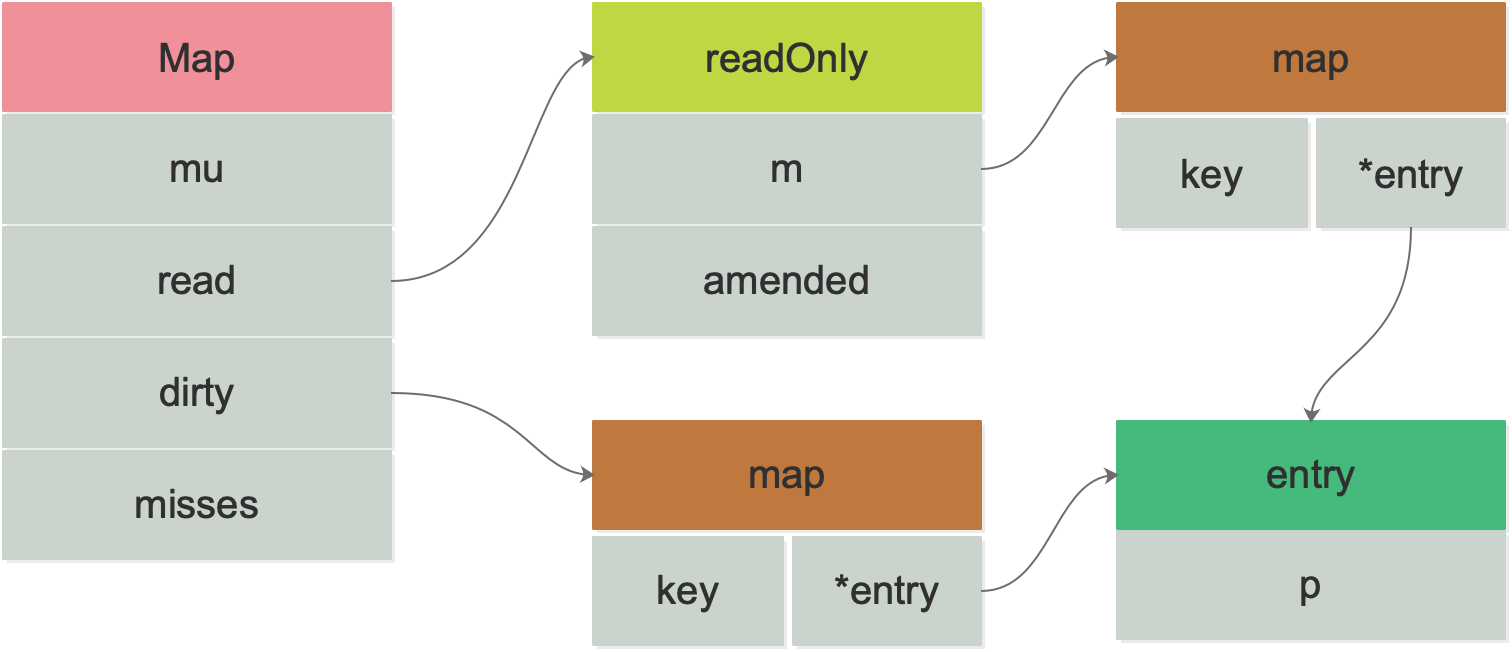
1type Map struct {
2 mu Mutex
3 read atomic.Value // readOnly
4 dirty map[interface{}]*entry
5 misses int
6}
互斥量 mu 保护 read 和 dirty。
read 是 atomic.Value 类型,可以并发地读。但如果需要更新 read,则需要加锁保护。对于 read 中存储的 entry 字段,可能会被并发地 CAS 更新。但是如果要更新一个之前已被删除的 entry,则需要先将其状态从 expunged 改为 nil,再拷贝到 dirty 中,然后再更新。
dirty 是一个非线程安全的原始 map。包含新写入的 key,并且包含 read 中的所有未被删除的 key。这样,可以快速地将 dirty 提升为 read 对外提供服务。如果 dirty 为 nil,那么下一次写入时,会新建一个新的 dirty,这个初始的 dirty 是 read 的一个拷贝,但除掉了其中已被删除的 key。
每当从 read 中读取失败,都会将 misses 的计数值加 1,当加到一定阈值以后,需要将 dirty 提升为 read,以期减少 miss 的情形。
read map和dirty map的存储方式是不一致的。
前者使用 atomic.Value,后者只是单纯的使用 map。
原因是 read map 使用 lock free 操作,必须保证 load/store 的原子性;而 dirty map 的 load+store 操作是由 lock(就是 mu)来保护的。
真正存储 key/value 的是 read 和 dirty 字段。read 使用 atomic.Value,这是 lock-free 的基础,保证 load/store 的原子性。dirty 则直接用了一个原始的 map,对于它的 load/store 操作需要加锁。
read 字段里实际上是存储的是:
1// readOnly is an immutable struct stored atomically in the Map.read field.
2type readOnly struct {
3 m map[interface{}]*entry
4 amended bool // true if the dirty map contains some key not in m.
5}
注意到 read 和 dirty 里存储的东西都包含 entry,来看一下:
很简单,它是一个指针,指向 value。看来,read 和 dirty 各自维护一套 key,key 指向的都是同一个 value。也就是说,只要修改了这个 entry,对 read 和 dirty 都是可见的。这个指针的状态有三种:

当 p == nil 时,说明这个键值对已被删除,并且 m.dirty == nil,或 m.dirty[k] 指向该 entry。
当 p == expunged 时,说明这条键值对已被删除,并且 m.dirty != nil,且 m.dirty 中没有这个 key。
其他情况,p 指向一个正常的值,表示实际 interface{} 的地址,并且被记录在 m.read.m[key] 中。如果这时 m.dirty 不为 nil,那么它也被记录在 m.dirty[key] 中。两者实际上指向的是同一个值。
当删除 key 时,并不实际删除。一个 entry 可以通过原子地(CAS 操作)设置 p 为 nil 被删除。如果之后创建 m.dirty,nil 又会被原子地设置为 expunged,且不会拷贝到 dirty 中。
如果 p 不为 expunged,和 entry 相关联的这个 value 可以被原子地更新;如果 p == expunged,那么仅当它初次被设置到 m.dirty 之后,才可以被更新。
整体用一张图来表示:
Store
先来看 expunged:
1var expunged = unsafe.Pointer(new(interface{}))
它是一个指向任意类型的指针,用来标记从 dirty map 中删除的 entry。
1// Store sets the value for a key.
2func (m *Map) Store(key, value interface{}) {
3 // 如果 read map 中存在该 key 则尝试直接更改(由于修改的是 entry 内部的 pointer,因此 dirty map 也可见)
4 read, _ := m.read.Load().(readOnly)
5 if e, ok := read.m[key]; ok && e.tryStore(&value) {
6 return
7 }
8
9 m.mu.Lock()
10 read, _ = m.read.Load().(readOnly)
11 if e, ok := read.m[key]; ok {
12 if e.unexpungeLocked() {
13 // 如果 read map 中存在该 key,但 p == expunged,则说明 m.dirty != nil 并且 m.dirty 中不存在该 key 值 此时:
14 // a. 将 p 的状态由 expunged 更改为 nil
15 // b. dirty map 插入 key
16 m.dirty[key] = e
17 }
18 // 更新 entry.p = value (read map 和 dirty map 指向同一个 entry)
19 e.storeLocked(&value)
20 } else if e, ok := m.dirty[key]; ok {
21 // 如果 read map 中不存在该 key,但 dirty map 中存在该 key,直接写入更新 entry(read map 中仍然没有这个 key)
22 e.storeLocked(&value)
23 } else {
24 // 如果 read map 和 dirty map 中都不存在该 key,则:
25 // a. 如果 dirty map 为空,则需要创建 dirty map,并从 read map 中拷贝未删除的元素到新创建的 dirty map
26 // b. 更新 amended 字段,标识 dirty map 中存在 read map 中没有的 key
27 // c. 将 kv 写入 dirty map 中,read 不变
28 if !read.amended {
29 // 到这里就意味着,当前的 key 是第一次被加到 dirty map 中。
30 // store 之前先判断一下 dirty map 是否为空,如果为空,就把 read map 浅拷贝一次。
31 m.dirtyLocked()
32 m.read.Store(readOnly{m: read.m, amended: true})
33 }
34 // 写入新 key,在 dirty 中存储 value
35 m.dirty[key] = newEntry(value)
36 }
37 m.mu.Unlock()
38}
整体流程:
- 如果在 read 里能够找到待存储的 key,并且对应的 entry 的 p 值不为 expunged,也就是没被删除时,直接更新对应的 entry 即可。
- 第一步没有成功:要么 read 中没有这个 key,要么 key 被标记为删除。则先加锁,再进行后续的操作。
- 再次在 read 中查找是否存在这个 key,也就是 double check 一下,这也是 lock-free 编程里的常见套路。如果 read 中存在该 key,但
p == expunged,说明 m.dirty != nil 并且 m.dirty 中不存在该 key 值 此时: a. 将 p 的状态由 expunged 更改为 nil;b. dirty map 插入 key。然后,直接更新对应的 value。 - 如果 read 中没有此 key,那就查看 dirty 中是否有此 key,如果有,则直接更新对应的 value,这时 read 中还是没有此 key。
- 最后一步,如果 read 和 dirty 中都不存在该 key,则:a. 如果 dirty 为空,则需要创建 dirty,并从 read 中拷贝未被删除的元素;b. 更新 amended 字段,标识 dirty map 中存在 read map 中没有的 key;c. 将 k-v 写入 dirty map 中,read.m 不变。最后,更新此 key 对应的 value。
再来看一些子函数:
1// 如果 entry 没被删,tryStore 存储值到 entry 中。如果 p == expunged,即 entry 被删,那么返回 false。
2func (e *entry) tryStore(i *interface{}) bool {
3 for {
4 p := atomic.LoadPointer(&e.p)
5 if p == expunged {
6 return false
7 }
8 if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
9 return true
10 }
11 }
12}
tryStore 在 Store 函数最开始的时候就会调用,是比较常见的 for 循环加 CAS 操作,尝试更新 entry,让 p 指向新的值。
unexpungeLocked 函数确保了 entry 没有被标记成已被清除:
1// unexpungeLocked 函数确保了 entry 没有被标记成已被清除。
2// 如果 entry 先前被清除过了,那么在 mutex 解锁之前,它一定要被加入到 dirty map 中
3func (e *entry) unexpungeLocked() (wasExpunged bool) {
4 return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
5}
Load
1func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
2 read, _ := m.read.Load().(readOnly)
3 e, ok := read.m[key]
4 // 如果没在 read 中找到,并且 amended 为 true,即 dirty 中存在 read 中没有的 key
5 if !ok && read.amended {
6 m.mu.Lock() // dirty map 不是线程安全的,所以需要加上互斥锁
7 // double check。避免在上锁的过程中 dirty map 提升为 read map。
8 read, _ = m.read.Load().(readOnly)
9 e, ok = read.m[key]
10 // 仍然没有在 read 中找到这个 key,并且 amended 为 true
11 if !ok && read.amended {
12 e, ok = m.dirty[key] // 从 dirty 中找
13 // 不管 dirty 中有没有找到,都要"记一笔",因为在 dirty 提升为 read 之前,都会进入这条路径
14 m.missLocked()
15 }
16 m.mu.Unlock()
17 }
18 if !ok { // 如果没找到,返回空,false
19 return nil, false
20 }
21 return e.load()
22}
处理路径分为 fast path 和 slow path,整体流程如下:
- 首先是 fast path,直接在 read 中找,如果找到了直接调用 entry 的 load 方法,取出其中的值。
- 如果 read 中没有这个 key,且 amended 为 fase,说明 dirty 为空,那直接返回 空和 false。
- 如果 read 中没有这个 key,且 amended 为 true,说明 dirty 中可能存在我们要找的 key。当然要先上锁,再尝试去 dirty 中查找。在这之前,仍然有一个 double check 的操作。若还是没有在 read 中找到,那么就从 dirty 中找。不管 dirty 中有没有找到,都要"记一笔",因为在 dirty 被提升为 read 之前,都会进入这条路径
这里主要看下 missLocked 的函数的实现:
1func (m *Map) missLocked() {
2 m.misses++
3 if m.misses < len(m.dirty) {
4 return
5 }
6 // dirty map 晋升
7 m.read.Store(readOnly{m: m.dirty})
8 m.dirty = nil
9 m.misses = 0
10}
直接将 misses 的值加 1,表示一次未命中,如果 misses 值小于 m.dirty 的长度,就直接返回。否则,将 m.dirty 晋升为 read,并清空 dirty,清空 misses 计数值。这样,之前一段时间新加入的 key 都会进入到 read 中,从而能够提升 read 的命中率。
再来看下 entry 的 load 方法:
1func (e *entry) load() (value interface{}, ok bool) {
2 p := atomic.LoadPointer(&e.p)
3 if p == nil || p == expunged {
4 return nil, false
5 }
6 return *(*interface{})(p), true
7}
对于 nil 和 expunged 状态的 entry,直接返回 ok=false;否则,将 p 转成 interface{} 返回。
Delete
1// Delete deletes the value for a key.
2func (m *Map) Delete(key interface{}) {
3 read, _ := m.read.Load().(readOnly)
4 e, ok := read.m[key]
5 // 如果 read 中没有这个 key,且 dirty map 不为空
6 if !ok && read.amended {
7 m.mu.Lock()
8 read, _ = m.read.Load().(readOnly)
9 e, ok = read.m[key]
10 if !ok && read.amended {
11 delete(m.dirty, key) // 直接从 dirty 中删除这个 key
12 }
13 m.mu.Unlock()
14 }
15 if ok {
16 e.delete() // 如果在 read 中找到了这个 key,将 p 置为 nil
17 }
18}
可以看到,基本套路还是和 Load,Store 类似,都是先从 read 里查是否有这个 key,如果有则执行 entry.delete 方法,将 p 置为 nil,这样 read 和 dirty 都能看到这个变化。
如果没在 read 中找到这个 key,并且 dirty 不为空,那么就要操作 dirty 了,操作之前,还是要先上锁。然后进行 double check,如果仍然没有在 read 里找到此 key,则从 dirty 中删掉这个 key。但不是真正地从 dirty 中删除,而是更新 entry 的状态。
来看下 entry.delete 方法:
1func (e *entry) delete() (hadValue bool) {
2 for {
3 p := atomic.LoadPointer(&e.p)
4 if p == nil || p == expunged {
5 return false
6 }
7 if atomic.CompareAndSwapPointer(&e.p, p, nil) {
8 return true
9 }
10 }
11}
它真正做的事情是将正常状态(指向一个 interface{})的 p 设置成 nil。没有设置成 expunged 的原因是,当 p 为 expunged 时,表示它已经不在 dirty 中了。这是 p 的状态机决定的,在 tryExpungeLocked 函数中,会将 nil 原子地设置成 expunged。
tryExpungeLocked 是在新创建 dirty 时调用的,会将已被删除的 entry.p 从 nil 改成 expunged,这个 entry 就不会写入 dirty 了。
1func (e *entry) tryExpungeLocked() (isExpunged bool) {
2 p := atomic.LoadPointer(&e.p)
3 for p == nil {
4 // 如果原来是 nil,说明原 key 已被删除,则将其转为 expunged。
5 if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
6 return true
7 }
8 p = atomic.LoadPointer(&e.p)
9 }
10 return p == expunged
11}
注意到如果 key 同时存在于 read 和 dirty 中时,删除只是做了一个标记,将 p 置为 nil;而如果仅在 dirty 中含有这个 key 时,会直接删除这个 key。原因在于,若两者都存在这个 key,仅做标记删除,可以在下次查找这个 key 时,命中 read,提升效率。若只有在 dirty 中存在时,read 起不到“缓存”的作用,直接删除。
LoadOrStore
这个函数结合了 Load 和 Store 的功能,如果 map 中存在这个 key,那么返回这个 key 对应的 value;否则,将 key-value 存入 map。这在需要先执行 Load 查看某个 key 是否存在,之后再更新此 key 对应的 value 时很有效,因为 LoadOrStore 可以并发执行。
具体的过程不再一一分析了,可参考 Load 和 Store 的源码分析。
Range
Range 的参数是一个函数:
1f func(key, value interface{}) bool
由使用者提供实现,Range 将遍历调用时刻 map 中的所有 k-v 对,将它们传给 f 函数,如果 f 返回 false,将停止遍历。
1func (m *Map) Range(f func(key, value interface{}) bool) {
2 read, _ := m.read.Load().(readOnly)
3 if read.amended {
4 m.mu.Lock()
5 read, _ = m.read.Load().(readOnly)
6 if read.amended {
7 read = readOnly{m: m.dirty}
8 m.read.Store(read)
9 m.dirty = nil
10 m.misses = 0
11 }
12 m.mu.Unlock()
13 }
14
15 for k, e := range read.m {
16 v, ok := e.load()
17 if !ok {
18 continue
19 }
20 if !f(k, v) {
21 break
22 }
23 }
24}
当 amended 为 true 时,说明 dirty 中含有 read 中没有的 key,因为 Range 会遍历所有的 key,是一个 O(n) 操作。将 dirty 提升为 read,会将开销分摊开来,所以这里直接就提升了。
之后,遍历 read,取出 entry 中的值,调用 f(k, v)。
其他
关于为何 sync.map 没有 Len 方法,参考资料里给出了 issue,bcmills 认为对于并发的数据结构和非并发的数据结构并不一定要有相同的方法。例如,map 有 Len 方法,sync.map 却不一定要有。就像 sync.map 有 LoadOrStore 方法,map 就没有一样。
有些实现增加了一个计数器,并原子地增加或减少它,以此来表示 sync.map 中元素的个数。但 bcmills 提出这会引入竞争:atomic 并不是 contention-free 的,它只是把竞争下沉到了 CPU 层级。这会给其他不需要 Len 方法的场景带来负担。
总结
-
sync.map是线程安全的,读取,插入,删除也都保持着常数级的时间复杂度。 -
通过读写分离,降低锁时间来提高效率,适用于读多写少的场景。
-
Range 操作需要提供一个函数,参数是
k,v,返回值是一个布尔值:f func(key, value interface{}) bool。 -
调用 Load 或 LoadOrStore 函数时,如果在 read 中没有找到 key,则会将 misses 值原子地增加 1,当 misses 增加到和 dirty 的长度相等时,会将 dirty 提升为 read。以期减少“读 miss”。
-
新写入的 key 会保存到 dirty 中,如果这时 dirty 为 nil,就会先新创建一个 dirty,并将 read 中未被删除的元素拷贝到 dirty。
-
当 dirty 为 nil 的时候,read 就代表 map 所有的数据;当 dirty 不为 nil 的时候,dirty 才代表 map 所有的数据。
参考资料
【德志大佬-设计并发安全的 map】 https://halfrost.com/go_map_chapter_one/
【德志大佬-设计并发安全的 map】 https://halfrost.com/go_map_chapter_two/
【关于 sync.map 为什么没有 len 方法的 issue】 https://github.com/golang/go/issues/20680
【芮神增加了 len 方法】 http://xiaorui.cc/archives/4972
【图解 map 操作】 https://wudaijun.com/2018/02/go-sync-map-implement/
【从一道面试题开始】 https://segmentfault.com/a/1190000018657984
【源码分析】 https://zhuanlan.zhihu.com/p/44585993
【行文通畅,流程图清晰】 https://juejin.im/post/5d36a7cbf265da1bb47da444
- 原文作者:饶全成
- 原文链接:https://qcrao.com/post/dive-into-go-sync-map/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
