深度阅读之《100 Go Mistakes and How to Avoid Them》
继《Mastering Go》 和 《Concurrency in Go》之后,这是我精读的第 3 本 Go 主题的英文书了。全书 390+ 页,从开始读到全部读完,快 2 个月了,😓。
前不久曹大连接发了几个关于《100 mistakes》的视频,多猜他大都是看看标题,看看代码,就知道要说什么了,并且很快就跳过去,速度飞快。我开始设想的是除了读懂内容,还想练习一下英语阅读,慢就慢吧。不过,我过后也确实加快了速度,毕竟人家半小时的进度我要两周,稍微有点离谱。
简单谈一下这本书:全书“凑”了 100 个关于 Go 的错误。有些是非常经典且常见的错误,例如在 for 循环中保存迭代变量的指针、并发 append slice 等等,书中做了非常详细的讲述。另外有一些错误则见得不多,有凑数的嫌疑,例如很多错误是不知道 xxx、不懂 xxx……读来稍微有点别扭。还有一些瑕疵的地方是第 8 章关于 M 的描述是错误的……
关于书名,作者还找了几个为什么要从 mistakes 中学习的理由:我们印象最深的知识点一定是在犯错的场景下学到的。
Tell me and I forget. Teach me and I remember. Involve me and I learn.
我们最近正在组织这本书的翻译,估计明年 5 月左右能上市,不过还是建议大家读读英文版。
以下是我在读书的过程中所做的一些笔记,记下我认为今后可能会遇到的坑。
- Go 很简单,但不容易掌握
Go is simple but not easy.
简单意味着易懂,Go 语法基本上花 2 小时就能全部看完。但是要想掌握它、写好它却不容易。比如,goroutine 和 channel 该简单了吧,但是使用 channel 出错的 case 数不胜数。
之前有篇讲 Concurrency bugs 的论文《Understanding Real-World Concurrency Bugs in Go》说:尽管人们普遍认为通过 channel 来传递消息更少出错误,但是论文里研究的 bug 表明,正好相反,用 mutex 才更少出错。
- The bigger the interface, the weaker the abstraction
Rob Pike说:The bigger the interface, the weaker the abstraction。当一个接口的方法越多,它的抽象能力越弱。像接口 Reader/Writer 为何很强大,因为它们就只有一个方法。
他还说:Don’t design with interfaces, discover them. 意思就是只有在实现过程中发现需要 interface 时才需要定义。是自下而上的过程,而非相反。
- net 包和 net/http 包并没有层级关系
可以认为是两个不同的包,它们仅仅是文件位置有层级关系而已。
- 包名要反映这个包能提供什么能力,而不是它包含了哪些内容。
函数名反映它做了什么,而不是怎么做。虽然命名一直是编程界的难题,但不断尝试好的命名也是必要的。日常的 util, common, base 这些包名其实并不好。任何对外暴露的内容:包、函数、方法、变量都应该给出说明。
- nil slice 的几个特点
不分配内存。对于一个函数的返回值而言,返回 nil slice 比 emtpy slice 要更好。
在 marshal 时,nil slice 是 null,而 empty slice 是 []。因此在使用相关库函数时,要特别注意这两者的区别。
nil slice 和 empty slice 不 equal。
以下代码中前 2 个是 nil slice,后两个不是。

- copy 函数拷贝的元素数量是 min(len(dst), len(min))
- 初始化 map 时,指定一个长度
它能给 runtime 以提示,这样后续可以减少重新分配元素的开销。并且要注意:这个长度并不是说 map 只能放这么多元素,这里面有一个公式会计算。
map 的 buckets 数只会增,不会降。所以当在流量冲击后,map 的 buckets 数扩容到了一个新高度,之后即使把元素都删除了也无济于事。内存占用还是在,因为基础的 buckets 占用的内存不会少。
关于这一点,之前专门写过一篇Go map 竟然也会发生内存泄漏?去讲,私以为比书里讲得更详细。
- 不要边遍历 map 边写入 key
在遍历 map 的过程中,新写入的 key 可能被遍历出来,也可能不被遍历出来,可能会与预期的行为不符,因此不要边遍历边写入。
下面这个例子输出的结果不确定:
1func main() {
2 m := map[int]bool{
3 0: true,
4 1: false,
5 2: true,
6 }
7
8 for k, v := range m {
9 if v {
10 m[10+k] = true
11 }
12 }
13
14 fmt.Println(m)
15}
- break 可以作用于 for, select, switch
break 只能跳出一重循环,因此要注意,break 是否跳到了你预想的地方。可以用 break with label 来解决。毕竟标准库里也这样用了:

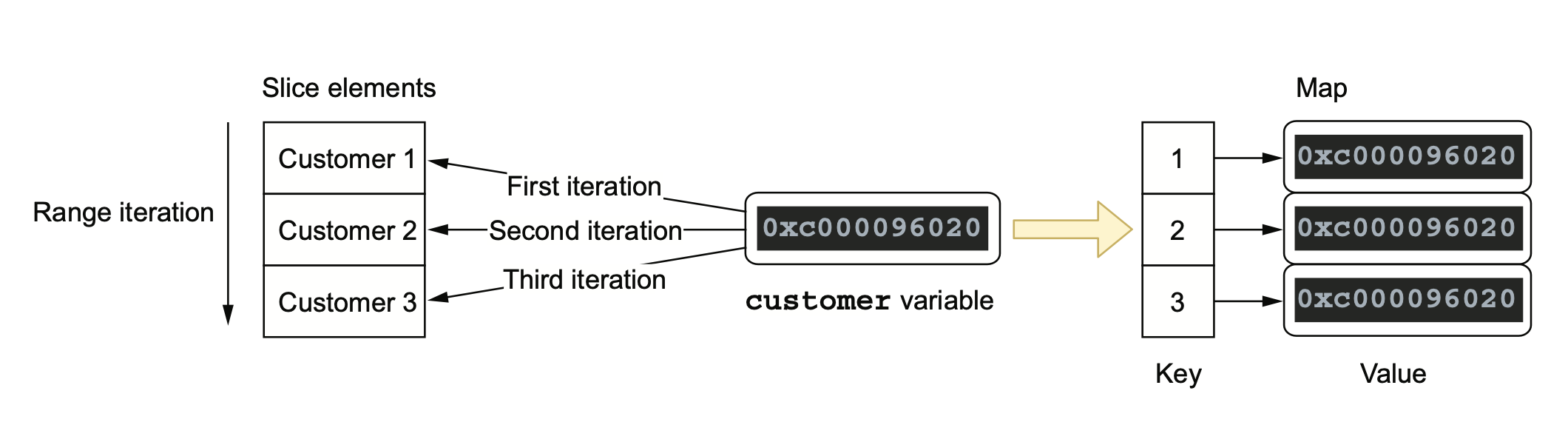
- for 循环加指针,老司机也会掉的坑
在 for range 循环里保存迭代变量的指针是一个非常容易犯的错误,Go 老手也会犯。原因是迭代变量至始至终都是同一个值,对它取地址得到的值也是相同的:

- rune 代表一个“字”,等于 Unicode 中的 code point。
因为在 UTF-8 中,一个字被编码成 1-4 个 bytes,因此 rune 被定义成了 int32。例如,汉字的编码是:0xE6, 0xB1, 0x89。
1func main() {
2 // len 返回的是 Byte 数量
3 // 3
4 fmt.Println(len("汉"))
5
6 s := string([]byte{0xE6, 0xB1, 0x89})
7 // 汉
8 println(s)
9
10 // 查看 rune 数量
11 // 1
12 fmt.Println(utf8.RuneCountInString(s))
13}
- TrimLeft, TrimRight 的坑
TrimLeft, TrimRight 会从 source string 里移除给定字符串里的字符(只要存在就移除),直到碰到一个不存在于给定字符串里的字符时结束;TrimPrefix, TrimSuffix 则要完全匹配,才会移除。Trim 等同于 TrimLeft+TrimRight。 13. 因为 Go 里面的 string 是不可变的,因此使用 += 来连接字符串时,其实是重新分配了一个新字符串。
使用 strings.Builder 时,可以用 Grow 方法来预分配内存,我自己之前一直忽略了预分配。因为它的底层是一个 slice,所以预分配 slice 是有必要的。
- string 和 []byte 之间的转换会有内存分配发生
所以除了一些 hack 方式的转换外,另外一个可替代的做法是在一些情况下直接用 bytes 包的方法,从而避免转换成 string:strings 包有的方法,byte 包也基本都有,比如 Split, Contains 等等。
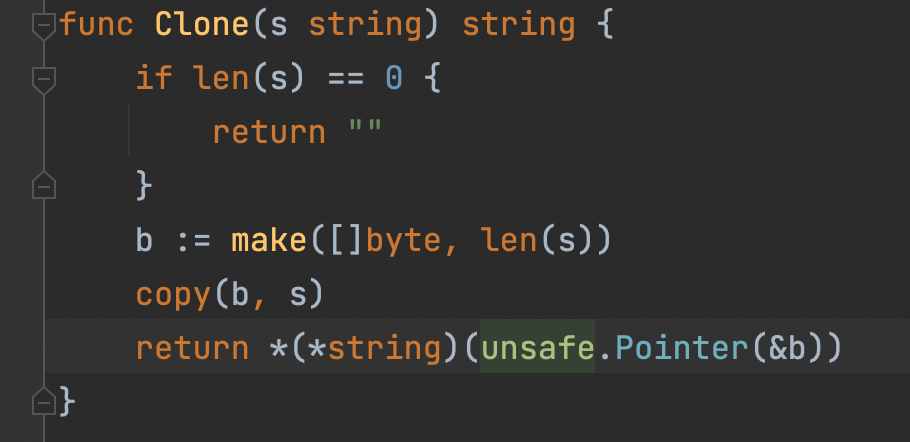
转 string 的做法在标准库中是这么做的,见 strings.Clone 方法:
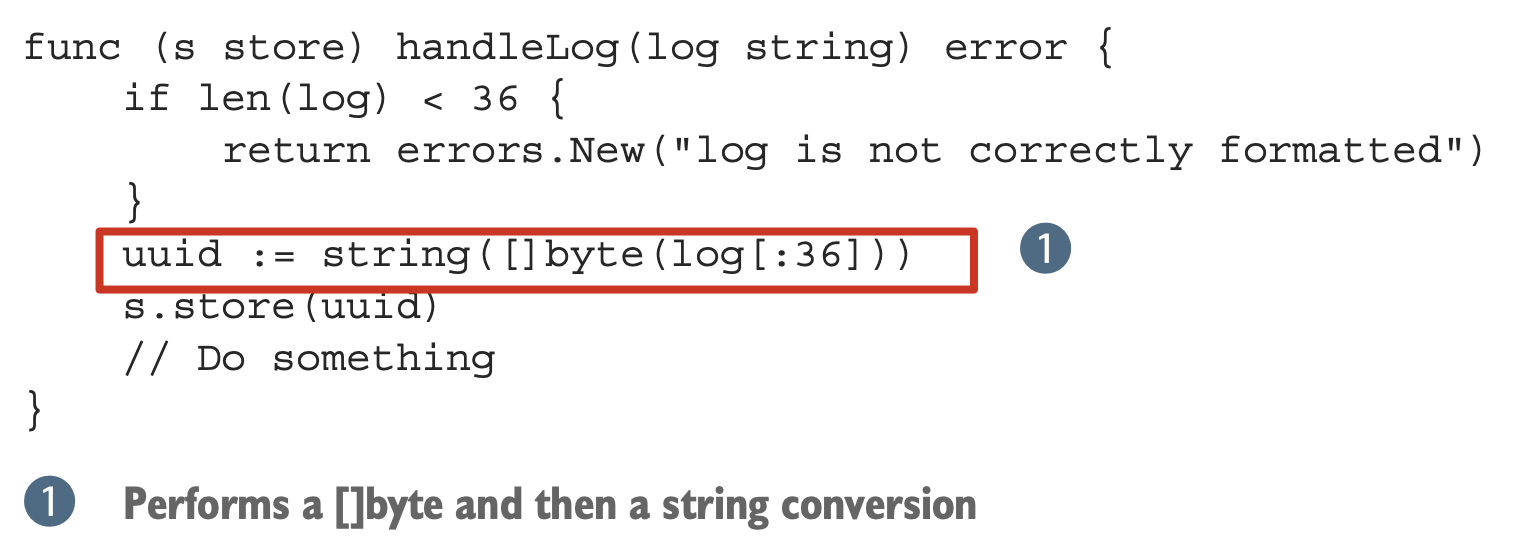
当我们需要取出一个 slice 里的小部分元素时,为了防止取字符串子串时内存泄漏,下面这种做法可能会在编译器中“误伤”,但这种转换是必要的,它发生了内存分配,因此和原字符串脱离了关系。另一种可选的方法是调用 strings.Clone 方法:
- 关于具名返回值。
什么时候需要给返回值命名呢?没有一个必须遵循的原则。取名字有两个场景:增加可读性(例如返回经度、纬度两个字段,如果不命名,鬼知道哪个前哪个后);利用它会自动初始化为零值,能让代码更短一些,当然,代码本身也得比较短。
另外,关于 return 时加不加名字。函数代码比较长时,还是带上比较好,增加可读性,不然看代码的人一直要记住返回值是什么。
在同一个函数里,统一返回值的风格,不要一会儿返回带名字的参数,一会儿又直接 return。
即使给返回值命名了,也不意味着一定要直接 return,还是可以带名字 return。
- 方法的语法糖
Having a nil receiver is allowed, and an interface converted from a nil pointer isn’t a nil interface.
这句话非常绕,也很容易犯错。前半句,当 receiver 是 nil 的时候,依然可以调用方法,因为实际上方法是一个语法糖。

当返回参数是一个自定义的 interface 时,尤其是自定义的 Error interface 时,直接返回 nil,而不要返回一个 nil 的 pointer,因为它不是 nil,且这往往造成后续的判空逻辑出错,这同样是一个很常见的错误。
- defer 一个 func 时,参数马上就会求值
然后这个函数调用就会被压栈,等函数 return 时再来执行,参数值用的是之前已经算好了的,如果参数不是指针,那程序的行为可能就不是预期的那样了。
这种情况还可以用闭包解决,闭包内里的参数就是在真正执行的时候才去求值的。下面这个闭包同时还包含一个参数:

- panic 和 error
一般 error 都是作为返回值的最后一个。有些错误处理方案不处理 error,企图直接在 defer 里看有没有 panic,这其实是模拟的 Java/C++ 等语言里对异常的处理方法。Go 一般不这么做。
panic 发生时,程序执行流程会一直“出栈”直到当前进程退出或者被 recover 掉。
为什么 recover 一定要写在 defer 里才生效呢?因为只有在 defer 里的语句才能在发生 panic 后也能执行。还有个问题是为什么 recover 非得要包一层才能有效呢?这是 Go 明确规定的。可能有两方面原因:recover 有一个返回值,它表示 panic 的原因,所以得有地方把它“打印”出来;Go 在实现上需要用到栈的层级关系。具体的就需要深入研究下源码。stackoverflow
- 当我们要返回一个确定的、预期内的错误时,应该返回一个预先定义的 error value,也被称为 sentinel error;当返回非预期的错误时,返回特定的 error type。前者用 errors.Is 判断,后者用 errors.As 判断。

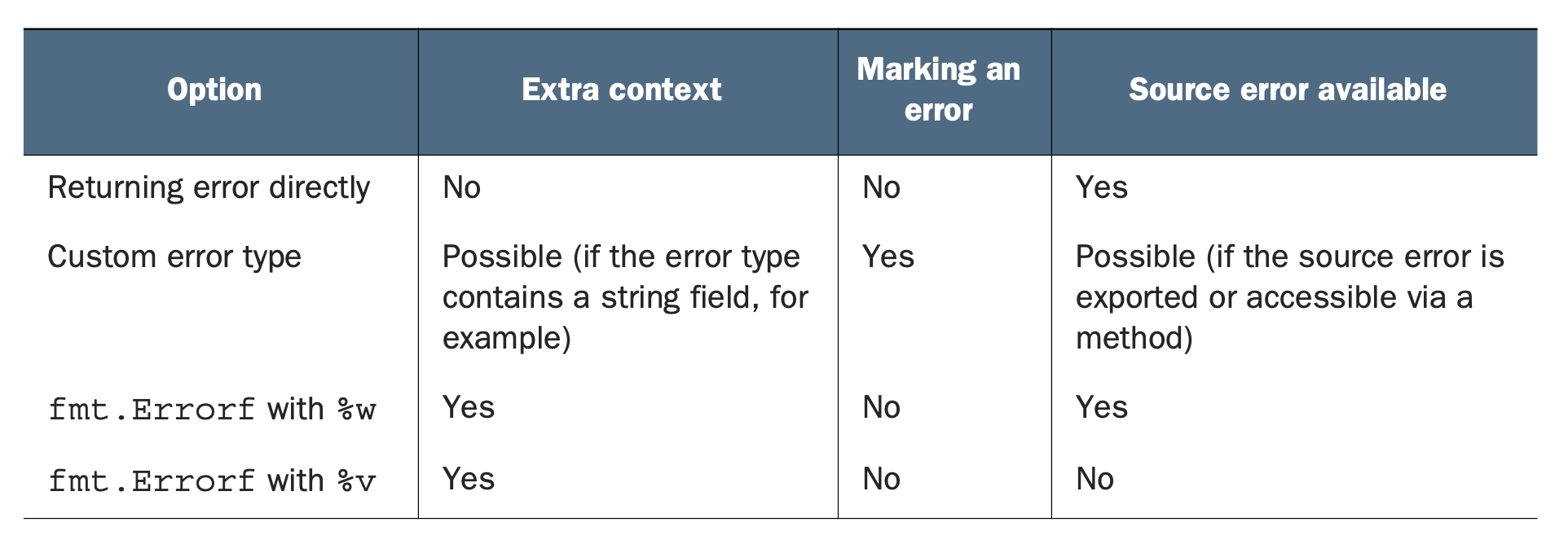
- 几种不同错误处理方式。用 %w 是 wrap,用 %v 是转换。前者可以看到 source error,可以用 As/Is 比较,后者看不到。
- 关于 context 取消
A Context carries a deadline, a cancellation signal, and other values across API boundaries.
context 被取消时,可以通过 Done() 方法返回的 channel 感知到。当 cancel 方法被调用、deadline 过期时,context 被取消。Done() 返回的 channel 被关闭。通过 Err() 方法可以感知到 context 为什么会被取消。
另外,context 是并发安全的。
channel 有一个魔法是:关闭 channel,可以让所有的 receiver 感知到。而向 channel 发送数据,只能有一个 receiver 能收到。

- context 的 key 类型如何设置
当设置 key/value 时,key 和 value 可以是任意类型;对于 key 而言,通常不是直接用字符串,而是用一个非导出的类型,这样不会发生冲突。

如何通过自定义的方式来继承一个 context 里的 value,而不继承它的信号。
1type detach struct {
2 ctx context.Context
3}
4
5func (d detach) Deadline() (time.Time, bool) {
6 return time.Time{}, false
7}
8
9func (d detach) Done() <-chan struct{} {
10 return nil
11}
12
13func (d detach) Err() error {
14 return nil
15}
16
17func (d detach) Value(key any) any {
18 return d.ctx.Value(key)
19}
- 闭包是一个使用函数体外变量的匿名函数。它和 goroutine, for 循环结合使用时,经常会出现意料之外的问题,老司机也经常在这里翻车。
1package main
2
3import "fmt"
4
5func listing1() {
6 s := []int{1, 2, 3}
7
8 for _, i := range s {
9 go func() {
10 fmt.Print(i)
11 }()
12 }
13}
14
15func listing2() {
16 s := []int{1, 2, 3}
17
18 for _, i := range s {
19 val := i
20 go func() {
21 fmt.Print(val)
22 }()
23 }
24}
25
26func listing3() {
27 s := []int{1, 2, 3}
28
29 for _, i := range s {
30 go func(val int) {
31 fmt.Print(val)
32 }(i)
33 }
34}
listing1 里因为是闭包,所以 Print 是在打印的时候才会真正求 i 的值,而 goroutine 什么时候执行是不确定的。因此打印时,可能是 2,也可能是 3,且 goroutine 打印的值还可能重复。例如打印出 233 时图解如下:
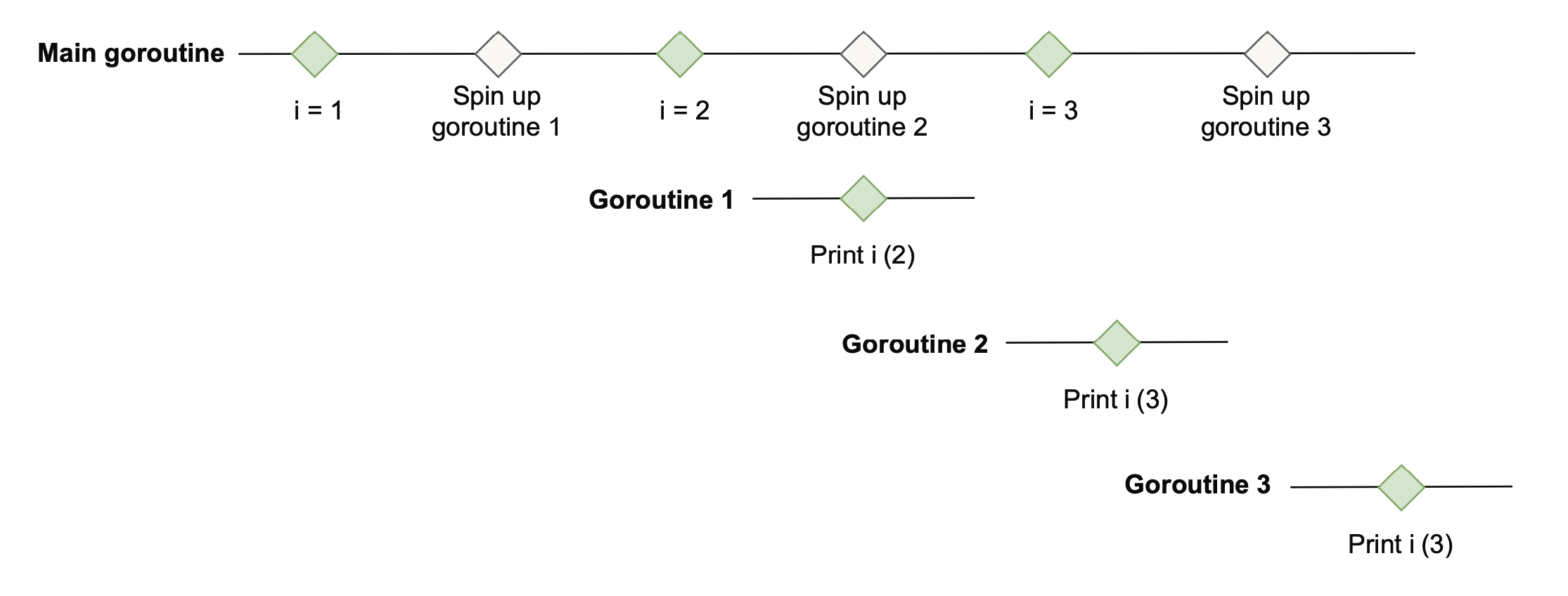
listing2 用本地变量,可以解决。
listing3 不用闭包,同样能解决问题。
-
用 map[K]struct{} 这种形式来表示 set 不光是节省内存,还能明确表达出这是一个 set 的含义;如果把 struct{} 换成 bool 意义就没这么明确了。
-
context 相关的并发问题
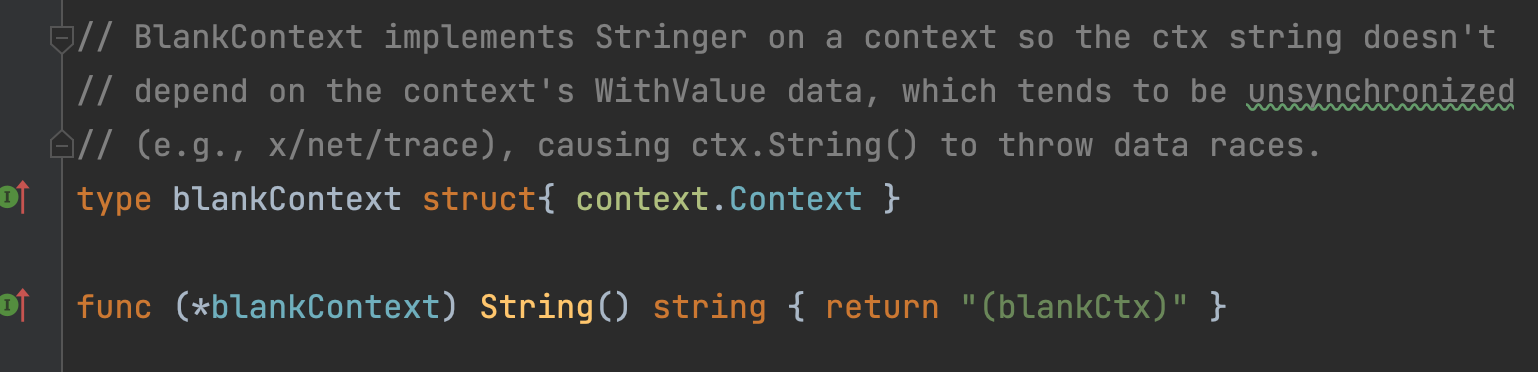
书里给了一个etcd里的例子,用 context 里的 k-v 做 key,然后遇到了并发(一个 goroutine 读所有的 value,另一个 goroutine 会更新某个可变的 value,例如 key 是一个指针,指向 struct)的问题,所以就自定义了一个 blankCtx 来拦截 String() 方法,消除并发问题。
这种问题应该还挺多的。context 里的 value 如果有可变类型,那么就会很容易导致 data race 的问题。
The fix https://github.com/etcd-io/etcd/pull/7816 was to not rely on fmt.Sprintf to format the map’s key to prevent traversing and reading the chain of wrapped values in the context. Instead, the solution was to implement a custom streamKeyFromCtx function to extract the key from a specific context value that wasn’t mutable.
- 为什么 slice 不能并发 append?
其实是看有没有同时 touch 同一个索引,也就是同一块内存。如果有的话就会有 data race 的问题。对于 map 而言,即使不是 touch 同一个 key 也会导致 data race。因为即使是不同的 key 也可能会被分到同一个 bucket。
当不同的 goroutine 并发写不同的索引时,不会发生 data-race。
我问chatGPT关于data race有什么坏处,得到的回答:
- sync.WaitGroup 的正确用法是:在父 goroutine 中调用 Add 方法,在子 goroutine 中调用 Done 方法。
sync.Cond 不太常用,它可以重复地给多个 goroutine 发送信号。与之相对的是, 关 channel 只能发送信号只能用一次。
A condition variable is a container of threads (here, goroutines) waiting for a certain condition.
- errgroup 是 golang 的一个库,它提供了一种简单的方式来处理多个并发任务的错误。它的主要作用是用来管理多个 goroutine,在所有的 goroutine 都完成后再进行错误处理。有两个方法:

-
time.After 会创建一个 channel,只会在过期的时候才会释放资源。
-
sql.Open 在有些 driver 下并不会连接到数据库,所以对于强依赖数据库的服务,需要先调用一下 Ping 或 PingContext 方法来保证数据库能连通,然后再启动服务。

这个我之前看项目的代码时,对这个还有一些疑问,认为没有必要。看书还是能涨知识的。
sql.Open 返回 *sql.DB struct,它的底层是一个连接池,我们需要设置连接池的下面这些属性,否则它们会用默认值(通常不太 work)。

最大连接数,不能太大,否则会把数据库打垮。
最大空闲连接数,需要增加,否则,流量一来,连接数不够,进而创建了一堆连接,因为 idle conn 数太少,最后又都释放掉。
最大空闲时间,默认是无限长,一旦碰到突发流量,连接一直保持在内存里,内存会爆掉。所以这个需要减少。
连接最大生存时间,如果需要负载均衡的话,连接的生存时间就不要太长,因为它会一直请求同一个负载。
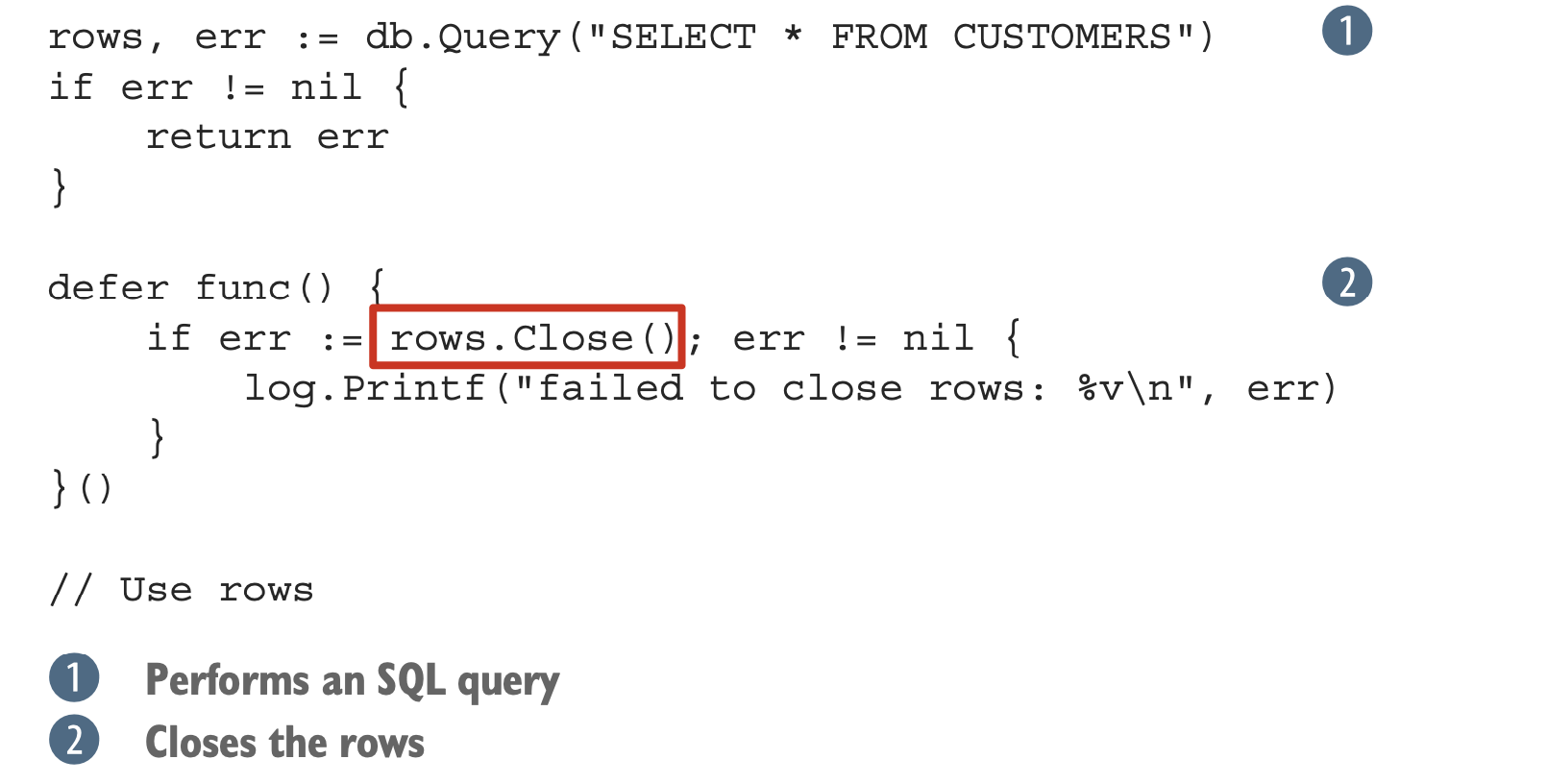
- 对于 http 包里的 resp,只要 err 为空的话,就可以用 defer 来关闭,而不用根据 resp 是否为空来决定是否关闭 body。

原因这里有解释:

只要是实现了 io.Closer 接口的资源,都应该在某个时间点调用 Close 方法,防止资源泄漏。
rows 没关闭的话,该连接不会被再次放到连接池里。
一个新手常犯的错误是使用默认的 http client,并且不设置任何超时的参数。

正确地如下:

另外,http client 底层也是有连接池的,所以相关的参数也得设置一下,默认的有问题,例如 http.Transport.MaxIdleConnsPerHost 的默认值是 2,就太小了。
http server 端的几个 timeout 参数设置:

另外,server 端的连接也可以设置 idle timeout,否则就只有等着 client 来关闭了。

- 发生 false sharing 的原因是,cache line 而非某个变量是 CPU 更新的粒度。
False sharing occurs when a cache line is shared across two cores when at least one goroutine is a writer.

- Reader 的 Read 方法的 API 设计成目前这样的好处是:[]byte 不会直接就在堆上分配,而是由调用者决定,它有可能会分配在栈区,从而提升性能。

- 查看函数是否被 inline
inline 的好处是除了节省函数调用的开销外,还可能让之前逃逸到堆上的变量重新回到 stack。


- pprof 可以在查看 heap profile 之前强制 GC,可以直接在命令参数里开启

pprof 的 block profile 默认不会开启,需要在代码里手动执行 runtime.SetBlockProfileRate() 设置多少次阻塞上报一次,才会开启,开启之后会在后台一直上报 goroutine 阻塞的事件。阻塞可能发生于:
-
Sending or receiving on an unbuffered channel
-
Sending to a full channel
-
Receiving from an empty channel
-
Mutex contention
-
Network or filesystem waits
pprof 的 mutex profile 也是默认不开启,开启办法是调用 runtime.SetMutexProfileFraction()。
如果怀疑有 goroutine 被阻塞了很久,可以用 debug=2 参数 dump 所有的 goroutine,一眼看出是否真被阻塞住了:

- 垫内存对 GC 阈值的影响不是线性的,但是直接改 GOGC 是。

- 原文作者:饶全成
- 原文链接:https://qcrao.com/post/100-go-mistakes-reading-notes/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
