🎉ChatGPT 与我合力开发 xargin blog archive
之前写的批量删除 chatGPT 对话的插件,最近我收到了一个五星好评:
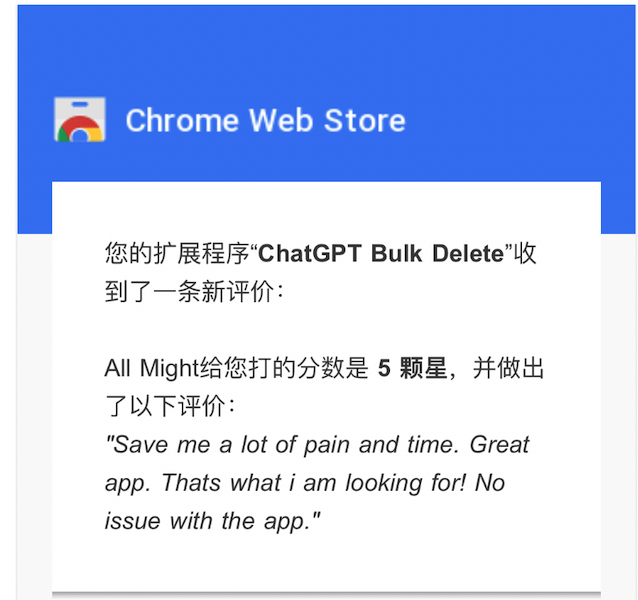
虽然不赚钱,交个朋友嘛,还是挺高兴的。而且借助 chatGPT,我是在与全世界的用户交流,想想就激动。
最近我发现自己让 chatGPT 帮忙写前端代码有点上瘾,这不又上架了一个 chrome 插件:Xargin Blog Archive。它的主要功能就是在曹大的博客 xargin.com 上添加一个 archive 页面。
由于 xargin.com 并没有 archive 页面,所以没法方便地点击历史文章,装上插件之后的效果是这样的:
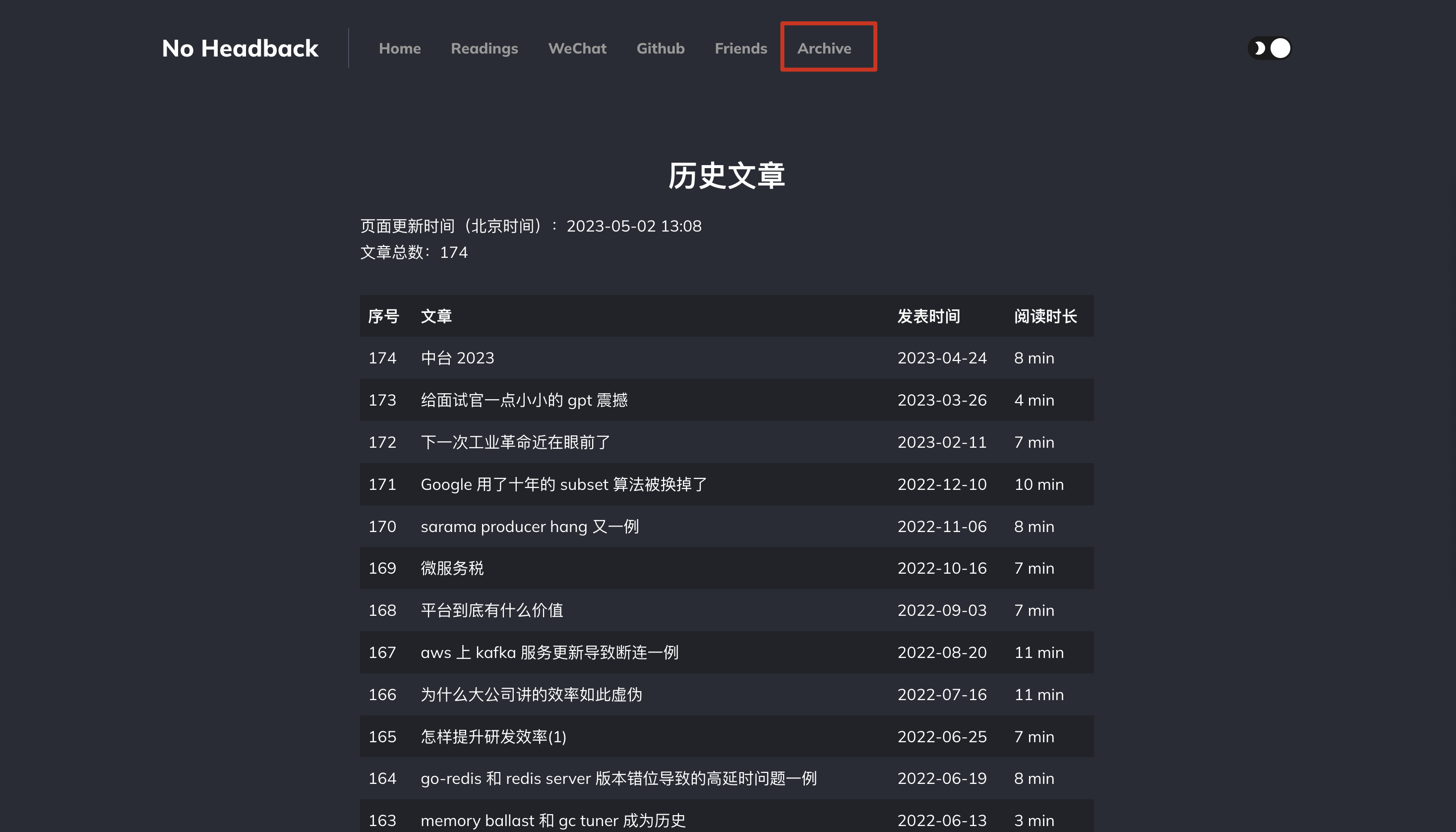
之前要想浏览历史文章只能一次次地点击“上一篇”,我还特地手动把曹大所有文章看了一遍,人工做了一个文章目录:
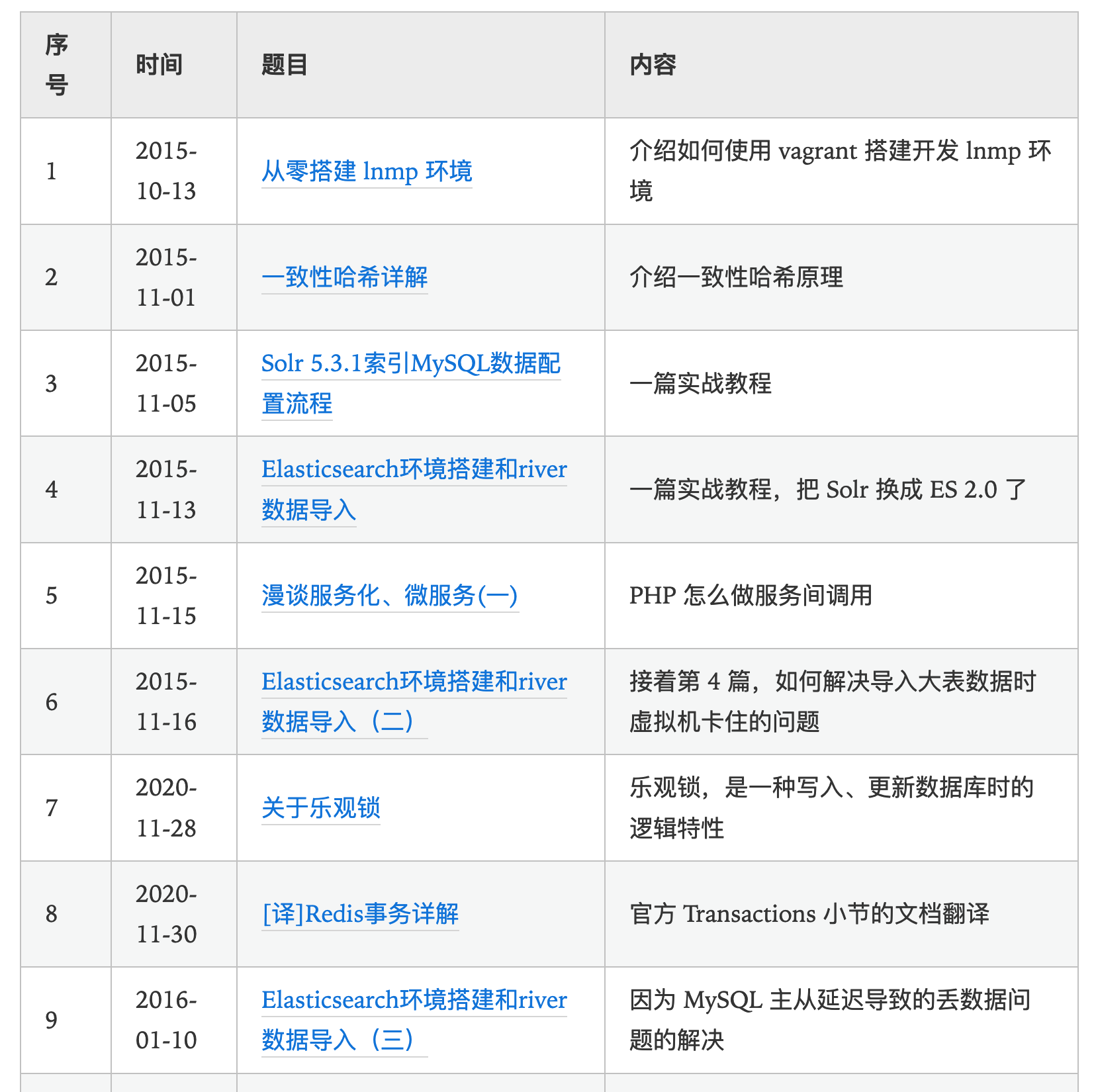
但我想要一个真的“archive”页面,但又不会写前端代码,而且也从来没写过 chrome 插件,也就一直没法真正上手去做。
当 chatGPT 出现后,写这样的代码就很简单了,只要清晰地描述出需求,剩下的就是一些简单的调试,改 bug 工作了。仅管描述清楚需求也不是那么简单,但是相比自己手动去 google、stackoverflow、垃圾文章里翻找一些代码相比,还是简单太多。
实际上,我的思路很简单:
- 写一个爬虫,从 xargin.com 上的第一篇文章开始爬标题,内容。
- 从内容里找到元素“Previous Post”,顺着链接找到上一篇内容。
- 不断重复爬上一篇文章,直到找到第一篇文章。到这里,就把所有的文章爬了下来。
- 将所有文章的标题、url、发布时间用 markdown 表格列出来,保存到一个 md 文件里,放到 github 仓库。
- 配置一个 github actions,定期运行爬虫,更新 md 文件。
- 最后写一个 chrome 插件,当检测到在浏览 xargin.com 页面时,将 md 文件拉取到本地,渲染成 html,插入到 achive 页面上。
要完成上面列的这些步骤需要的都是很通用的“能力”,比如写爬虫、将 md 渲染成 html,都是大家做烂了的工作,这种事情让 chatGPT 来帮忙,简直不要太容易。
实际上,我也是这么让 chatGPT 一步步地来做的,非常顺利。
唯一费了一些时间的是,我想调整 archive 页面的风格以适应暗黑模式。不过这个过程中我也跟 chatGPT 学到了暗黑模式的原理。
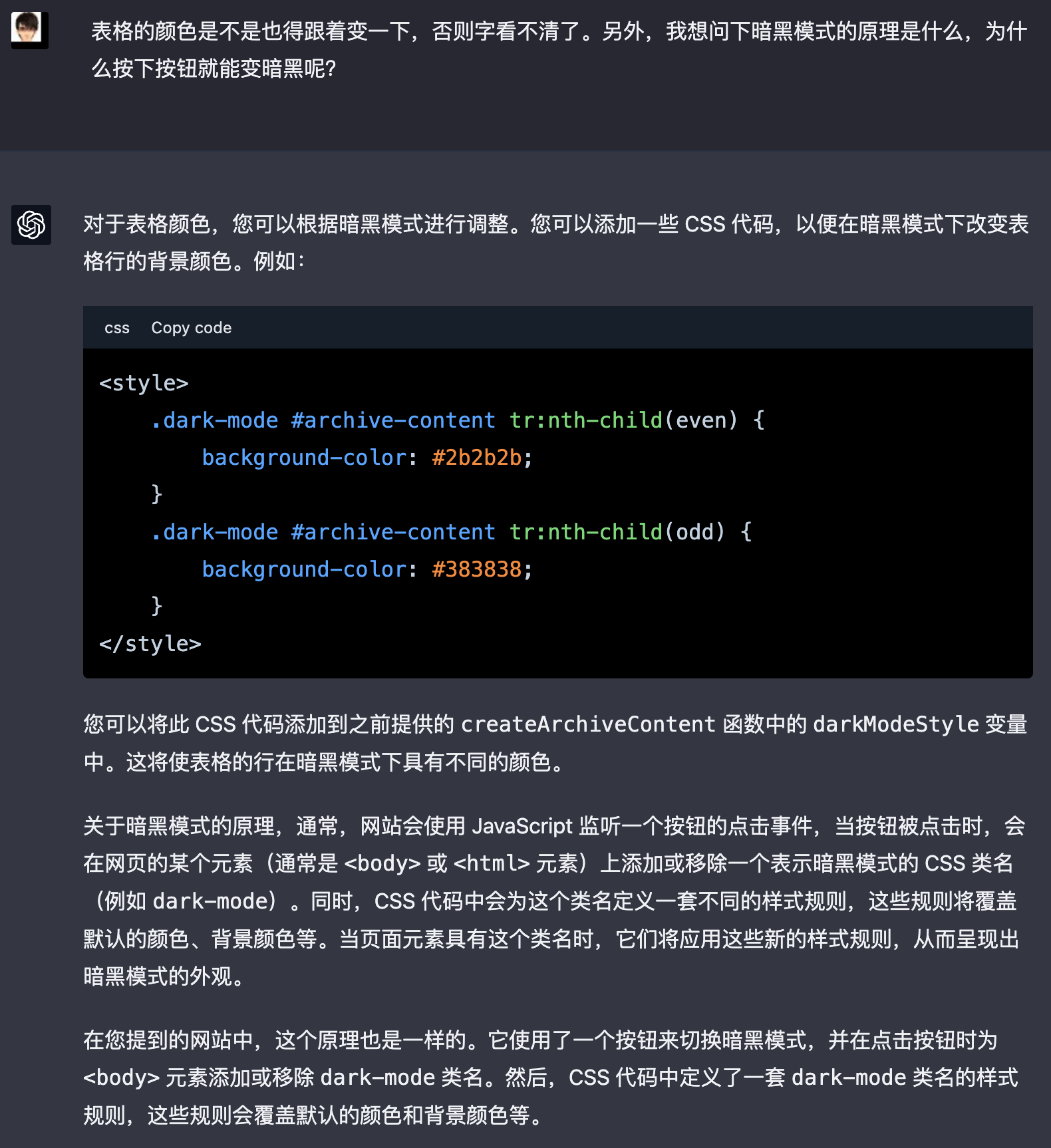
我建议读者们都去安装这个插件,这样阅读曹大的文章时就更加方便了。如果想要学习写这样的插件,我把和 chatGPT 的对话放在这里,各位可以自行研究。
对每个程序员来说,做出自己的作品都是一个梦想,这两个小作品算是一个小的开始。
- 原文作者:饶全成
- 原文链接:https://qcrao.com/post/develop-xargin-blog-archive-with-GPT-4/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
