那些年曹大写的文章
某天晚上看到曹大在群里指点江山,折服。感叹为何曹大如此渊博,遂决定从头到尾研读完他所有的博文。
前后共花了一个月的时间,今天终于读完了(2020-11-24~2020-12-26),总共 118 篇。从 15 年 10 月 31 日开始的第一篇,到今天,总共写了 5 年多的时间。基本上每半个月产出一篇,非常稳定。
从最初讲具体的工作,例如将 MySQL 数据导入到 ES,到近期的《中台的末路》、《架构的腐化》、《工程师应该怎么学习》等名篇,水平一步步提高,视野也在一步步变大。
这些博文里很多内容都是从工作中提炼、总结出来的,这需要对自己所做的工作非常熟悉,并且需要做很多思考才行。这对我们而言,是有启发的。
还有一些是论文或文档的翻译,翻译它们而不是仅仅看一遍,对我们深刻理解内容是很有帮助的。连曹大都这样做了,我们有什么理由不做呢?
总的感受是,我们需要不断思考、反思、总结,并且持续不断地写出来。在所有文章里,如果只推荐一篇的话,那无疑就是《工程师应该怎么学习》这篇。其中最激励我的三段是:
人这一辈子,最重要的是能把路越走越宽。对于工程师来说,能够锻炼软技能的场合其实不是很多,但也不代表完全没有。即使没有也可以自己创造机会,例如组内、组间、部门内的技术分享都是不错的机会。
更大规模的技术分享可能因为主办方“势力眼”,在你级别不高或者影响力不大的时候,不提供给你这样的机会,但是作为一个向上的人,迟早会有走到这一步的一天。你所要做的是提前做好准备,在那一天到来的时候,在聚光灯下旁征博引,谈笑风生。
祝大家都能成为更好的自己!
我们只有保持终生学习的姿态,才有可能不被时代抛弃。
If you don’t keep moving, you’ll quickly fall behind.
下面是详细的文章内容介绍,最后有一张表格,列出了所有的文章链接和概览。因为 xargin.com 没有 archive 功能,所以这篇文章算是全网最全的、最方便的博客入口。
第 1 篇是 15 年 10 月 31 日开始的,到今天已经 5 年了,主要讲如何使用 vagrant 来搭建一套 lnmp(linux/nginx/mysql/php)开发环境,解决一些诸如只用线上才出现的 bug,以及新同学如何能快速搞定开发环境。
第 2 篇主要讲的是一致性哈希。我又查了下其他资料,总结下一致性哈希的优点:当增减 server 时,可以移动最少的 keys;因为数据是均匀分布的,所以更容易水平扩展。现实世界中,比如 Amazon’s Dynamo 数据库的分区组件、Apache Cassandra 跨集群的数据分区等等都用到了一致性哈希。
第 3 篇是将 MySQL 里的数据导入到 Solr 来满足一些特定的查询需求。
第 4 篇把 Solr 换成 ES,再来一次。
第 5 篇主要内容是说用 PHP 实现服务发现很难,不如 Java 那样方便。人家亚马逊的贝索斯在 2002 年就要求服务化,而阿里则是 2009 年则开始的。
第 6 篇主要内容是讲从 MySQL 导入大量数据时,碰到 GC 问题,导致连登陆都不行,最后通过加大 JVM 的运行时内存解决;Stop the world 机制简称 STW,即在执行垃圾收集算法时,Java 应用程序的其他所有除了垃圾收集帮助器线程之外的线程都被挂起;思想其实很朴素,用空间来换时间。
第 7 篇是关于乐观锁的内容,悲观锁用 select for 先锁定记录,然后再 update 更交换机数据;而乐观锁则比较前后的版本(例如订单,也可以比较 status)来解决并发更新时的数据覆盖问题。记住这个时间点,5 年前,曹大刚听说乐观锁^_^。
第 8 篇是一份 Redis 事务相关的文档翻译。主要内容有事务的使用、事务的错误、使用 watch 等。
第 9 篇还是一个连续剧,书接第 6 篇,在实际操作的过程中,将 MySQL 的数据导入到 ES 中遇到的导入数据有丢失的问题,主要原因是有主从延迟。处理办法就是每次都去向前多取一点:select * from [业务表] where update_time > date_sub(now(), 10 minute);。嗯,曹大会刻意总结在工作中遇到的问题及思考的解决方案,即使看起来比较简单。
第 10 篇其实也是一个续集(一致性哈希),书接第 2 篇,主要讲了 2 种缓存客户端如何生成虚拟节点的算法。并且,从这篇文章得知,PHP 是没有什么可以全局复用的全局变量的,所以每次 web 请求从 nginx 到 cgi 都会重新走各种 web 框架的 index.php。
第 11 篇主要是总结了在开发的过程中遇到的问题及解决方案,它同时也是曹大在公司做过的分享。比较重要的点有:没有填 update_time 而采用了 create_time,且由于主从同步或者时钟或者其他问题导致的“工单系统是有可能在未来创建过去一段时间的工单的”,或者说“一个时刻创建了在这个时刻之前”,这个是通过每次都向前多取 10 分钟的变更数据。还有一个点是每天低峰期删数据导致的大量删除 binlog 会对系统造成压力。另外,这时就已经用了 gin 框架了。
第 12 篇是对当时同步 MySQL 和 ES 的方案的一个总结反思,说明了优点和缺陷。嗯,估计是最后一篇了。前后也有四、五个月了。
第 13 篇曹大喷了一个 php 框架 laravel 里的一个实现:闭包套闭包在函数调用的时候类似于递归调用,也存在压栈压爆的问题。最后一段:没错,拿技术解决问题,但是不要为了炫技而炫技。(特别是你的特技可能连一个“丑陋”的解决方案都打不过。找到一篇 Go 相关的责任链文章,对照看一下。
第 14 篇是看一个用 C 写的消息队列的源码。重点在于曹大对于“如何做分布式”的总结和思考:proxy 和 smart client。
第 15 篇讲的是如何设计一个灰度发布系统。从作用到分桶/分类策略,到用哈希算法对 key 进行哈希分桶从而实现千分比灰度。最后还提了几个问题并作了解答:使用 md5 和 sha1 不能保证均匀分布怎么办?如何选取分桶?使用 md5 或者 sha1 对 CPU 消耗太高怎么办?学到了两个如何对字符串算 md5 和 sha1 的命令:
1echo -n 15810321343 |openssl dgst -sha1
2md5 -s 15810321343
3
415810321343
5
6md5=>
705eadde36e5e5c3a00015a8f07d98d6b
8
9sha1=>
107962e1ba260de074ef895af44c62ad353ee36c2c
第 16 篇从数据库、检索服务、日志三个方面来谈 ES 能做的事,以及优势和限制。企业内部使用的 elasticsearch 是提供垂直搜索的一种方案,内容可能是一些结构化的数据,而不像大搜索那样都是杂乱的内容。数据库层面,查询条件可以转化为 bool 查询;单表 count 也容易解决;但 ES 不能实现 Join,事务。在检索服务层面,集群便可以非常方便地进行动态扩展,数据也不容易丢失;缺点是分词不是很科学。日志方面,ELK,每天建一个索引。
第 17 篇介绍了曹大自己开发的工具:elasticsql,使用 SQL 来查询 ES,目前 629 星。工作中遇到了问题,然后就手动开发一个工具,并且写文章总结,赞!
第 18 篇讲迅雷。文件会按 16KB 进行切分,每个文件块用 sha1 算法计算一个哈希值,用作小块的校验。将一个文件的所有小块的 sha1 连接得到的字符串再进行 sha1,得到整个文件的 id。之后简单讲了 server hub、peer hub、file server 的工作原理。因为迅雷成立时,互联网上的轮子并没有那么多,所以很多都得自研,文档也不全。最难解决的问题不是 P2P 下载,而是各种乱七八糟的 case。
第 19 篇列出了实际工作过程中碰到的各种低级的做法。我自己印象深刻的且之前没碰到过的有:滥用回调,增加系统复杂性;访问数据库不做批量;树形结构的表结构设计问题;工作流系统update不判断修改前的状态;抱怨接口性能是语言问题。嬉笑怒骂,皆成文章。
第 20 篇,把 logstash/kibana/elasticsearch 之类的东西统统变成 5.0 的过程中,遇到的一些问题及解决。
第 21 篇,公司登陆验证用的 Google Authenticator 来做校验的原理。也就是将一个 key 分发给某个具体的帐户,然后服务端和客户端可以每隔 30 s 算一个 token。将 token 和帐户验证即可确定身份。
第 22 篇,翻译的一个后 GitHub 上的后端面试项目,并给出一些问题的回答。这些题基本都是比较开放的问题,很少一问一答这种。5 年前的了,不过我看原项目地址 7 个月前还有更新。
第 23 篇,HTTP 中间件的形式如何写。这里给出了一些前置、后置、耗时统计的控制的例子,不过最后给的一个例子有点问题,不是太好理解。我找到了一篇叶剑峰大佬写的比较好理解的,能直接运行的例子。可以看到,《Go 语言高级编程》中也有这篇内容,可见平时的积累是非常重要的。
第 24 篇是问题 kafka 消息重复问题的排查,其实也没有各种现场排查,最终仅通过文档的说明就发现了问题:消费者在 poll 的时候才发送心跳,那如果处理消息的时间稍长就会被判失活,导致将正在消费的 partition rebalance 给其它消费者。因此解决办法就是升级到 0.10。这也告诉我们不要太快使用新发布的软件,因为有很多问题还没有生产环境中发现。
第 25 篇又是一篇吐槽文,工作中有时总是会遇到太“笨”的合作方,人家不会转一点脑子,什么问题都来问你,本来你就已经清楚地说明了。但一旦有什么在他们预期之外的事情,他就会来麻烦你。文中给出一些应对的办法,这当然需要后端去学习一些前端知识。工程师,终身学习是基本的。
第 26 篇,讲的是 redis 的 SDS 是不是二进制安全的。简单来说,通过使用二进制安全的 SDS,而不是 C 字符串,使得 Redis 不仅可以保存文本数据,还可以保存任意格式的二进制数据。起因是看到群里有人看到 redis 里有 strlen 的调用,就怀疑 redis 的 SDS 的二进制安全是不是真的。之后,一番实验和看代码,发现真正调用 sdsnew 函数的是在内部字符串用或者是测试用。
嗯,2016 年的博客看完了,总共 26 篇,基本两周一篇的节奏。
第 27 篇,是一篇译文。Redis 客户端和 Redis 服务器使用 RESP 协议通信,RESP 是 REdis Serialization Protocol 的简称。虽然 redis 协议设计得十分对阅读友好(human readable)并且十分容易实现,但实际实现起来和二进制协议的性能依然比较接近。例如,RESP 使用了前缀的 length 来传输 bulk 数据,所以没有必要像 JSON 一类的数据结构需要通过扫描来查找特殊字符,也没必要在发送数据的时候给数据加上引号(quote the payload)之类的。
第 28 篇,在某个本来想打游戏度过的周末,听说有 B 站的分享,于是去听了,结尾感慨:本来用来打游戏的周末又学了不少东西。整篇文章就是对这次分享的一次总结,其中又结合自己平时的思考。有一点是讲业务和基础架构绑在一起的好处。
第 29 篇,发现曹大有个习惯比较好,就是经常会翻译一些比较重要的文档。因为人总是容易遗忘,即使某个东西你现在很清晰,过了一段时间之后就会忘记。我想记住的具体的知识点就是:leader 会维护一个 in-sync replica (ISR) 的集合:是和 leader 的进度完全一致的那些 follower。其他的先不深究。
第 30 篇是一篇思考,关于系统如何处理错误,直白一点是如何向用户、向研发展示错误。应该管用户一些提示,而不是直接白屏,用户在故障之后恢复时能正常使用系统,而不是像有些权限系统设计的那样缓存个几天。对研发而言,根据错误能快速定位到错误的地方是最重要的。开头整理的一些错误场景总结如下:依赖组件挂了;依赖服务挂了;依赖方超时了;调用方的参数有问题;调用方的参数无法正确地通过校验;用户的某种操作在业务逻辑上不具有合理性,不能够接着让他执行下去;程序自身出错了,比如数组越界,对字符串和数字进行加和操作,或者是把 null 当成了某种合法的数据结构,通过点或者下标来获取某种属性。
第 31 篇,吐槽 Go 包非中心化管理的一些问题。最主要的一个问题是不好和开源项目“合作”的问题。
第 32 篇,介绍了分布式如何实现。首先是用 MySQL 实现,但解决不了租期的问题;接着用 redis 的 setexnx 命令,也有一个问题是:因为 redis 的主从同步是异步行为,在主上加锁成功,数据没有同步之前 master 挂掉了,那之后就可能会有多个实例(用户进程)持有锁,这显然不是我们希望的。(这里我的理解是其他用户进程会能向新主申请到锁);然后就是 redis 的作者提出了 Redlock 的加锁方法。
第 33 篇,使用代码示例讲解如何使用 parser 包做一些“高级”的事情:基于 ast 做很多静态分析、自动化和代码生成的事情,非常酷炫。
第 34 篇,利用 MySQL 的 information_schema 表来自动生成代码,依然很酷炫。
第 35 篇,讲 awesome go 的入选标准,主要关注两方面:1. goreport(包含 gofmt/go_vet/gocyclo/golint/license/ineffassign/mispell) 的结果;2. 测试覆盖率(coveralls,或者 gocover)。
第 36 篇,17 年 6 月份,那时我快毕业了。当年如日中天的 ofo 也早已经一地鸡毛,用户的押金也得到几百年之后才能还清。想起那时的创始人何等风光,如今安在?本问主要探讨密码锁的一些方案设计。
第 37 篇,关于 pprof 和火焰图的使用,嗯,曹大少有的教程类文章。这里有个如果涉及到 http handler 的压测,profile 的时候可以有技巧地把 Write/Read 的开销除开。
第 38 篇,公司都是要盈利的,都有自己的业务,业务驱动其实是常态,老板只关心有没有实现想要的功能,你如何实现,实现的代码质量如何这些并不重要,这也是现在你看到的公司的各种垃圾代码,这个问题也没法解。但对于个人而言,多看好的开源代码、多看《重构》这样书,以及使用 test 等方法能一定程度上解决问题。
第 39 篇,一个比较常见的问题,之前我也写过一篇类似的,当时我用的一个主要工具就是:perf top。
第 40 篇,回顾从 07 年入校以来的点滴,真情流露。曹大多才多艺!
第 41 篇,先是场景引入(今天刚好看到 caoz 讲的如何做分享),再层层递进。得出如果在内存中计算交集的一个方法:map[int]int。
第 42 篇,讨论阿里的一个开源库 ApsaraCache(类 redis) 所做的优化是如何实现的。主要有两点:增加对 MemCache 的支持;优化短链接。
第 43 篇,举了两个 Go 语言中 panic 无法被用户 recover 的情况:并发 map 读写;reflect.Call。结论:go 服务不用 supervisor 又不加监控就等着被开除吧。哈哈哈~
第 44 篇和第 45 篇是关于《Clean Architecture》的读书笔记,摘一句:对于商业公司的金主来说,软件系统有两方面的价值,一方面是软件的行为价值,也就是指软件的业务功能;另一方面是软件的结构,指软件的架构,易变性,可维护性,属于软性价值。软件工程师的职责是保证系统两方面的价值都能够达到最大。但是实际情况是,大多数人就只会聚焦在某一个方面,顾此失彼。
第 46 篇,宣告《Go 语言高级编程》正在搞,而且会继续搞完。周末写完了 router 一节。
第 47 篇,讨论了部门内的一个不均衡的负载均衡算法。数学证明的部分没太看懂~
第 48 篇,除了拿 debugger 来 debug。还可以用 debugger 来了解了解程序运行的机制,或者用 disass 来查看程序运行的汇编码。在查资料的时候,看到鸟窝写的文章:最近看到滴滴的工程师分享的使用debugger在调试Go程序,我觉得有必要在尝试一下这方面的技术了。估计说的就是曹大这篇。
gc 编译器产生的代码可能会包含内联的优化,这不方便调试器调试,为了禁止内联, 你可以使用 -gcflags “-N -l” 参数。
我跟着这篇讲 lldb 调试的文章走了一遍调试。设置断点有点问题,没完事做完。
这篇文章里还介绍了 dlv 的功能。由于好久没用到这些工具,暂时先不深入了。
第 49 篇,是对业务系统的接口上的思考,从功能上来说,可以抽象成 SQL。但实现起来,并且对用户友好,可能并没有那么简单。最后结论:支持什么 SQL/GraphQL 啊,thrift 大法好。
第 50 篇,这又是一篇译文(还是挺多的,所以这也是一种学习方法),关于 Go 汇编的。后来曹大在 Go 夜读上的 Go 汇编分享,这篇文章亦有贡献。
第 51 篇,关于协作式和非协作式抢占调度的特点以及关系。Go 实际上在 1.14 才真正实现了抢占式调度,使得 for 无限循环在 GC 的时候不会阻塞整个进程的执行,从而“卡死”。
第 52 篇,曹大开始进行源码阅读了,记住这个时间:2018-04-05。这篇文章开始会简单展示核心的关于 channel 的代码,包括读、写、关闭等,后面就主要是源码注释了。学到了一个在线的 markdown 编辑工具,好处是可以和 dropbox、github 绑定。
第 53 篇,启动流程分析。由于之前我已经追求一遍相关代码,不深入研究。
第 54 篇和第 50 篇来源于同一个 github 项目,但作者已经跑路了。文章是比较硬核的,作者的研究方法是从 binary asm 反推实现原理。
第 55 篇,这是曹大在 Go 夜读上所做分享的原文,牛逼。领先我们好几年。
第 56 篇,思考业务系统中的问题及解法。讨论的问题是如何收集、计算主业务流程相关的指标。开头由 DDIA 一书引入话题,然后说明场景,再谈解决办法,然后说问题,再来说方法……从这里也可以看到,曹大在 18 年就已经看完了 DDIA。我则是今年才开始看这本书,差距。
第 57 篇,G 和 P 的状态流转图,用的是“自动”生成的。相比我之前手动画的,改起来也比较容易。
第 58 篇,什么 TDD,BDD,DDD 都是浮云,事故驱动开发才是王道。不出事故,一切都好说,管你什么代码质量,有什么用?出事故,那马上得复盘、甚至罚款。结尾列出的三个案例也是值得好好看,尤其是尽可能要用 defer。
第 59 篇,喜大普奔,从 hexo 升级到 ghost,且升级了 gitalk 评论系统,直接和 github 打通。
第 60 篇,讲的《Concurrency In Go》里的一个活锁的例子,原因是没有协调好加锁的顺序,且使用的是 tryLock 的这种形式,即没有加锁成功,就先返回失败,再尝试。当然,如果不是 trylock 的话,不一致的加锁顺序会直接导致死锁。
如果已经发现了活锁导致的问题,解决手段很简单,只要规定好加锁顺序,并且大家都按同样的顺序去加锁就可以了。活锁比较麻烦的是难以发现,因为在活锁状态下的程序实际上看起来很正常,只是性能表现会稍微差一些。
另外,不得不说一句,我是今年才看的这本书。差距啊!
第 61 篇,毕业四年,列出的计划单,非常叼。我印象比较深刻的有:有个人的稳定的科学查资料方案,改天有机会当面请教一下。
第 62 篇,调度器的源码分析,由于我已经写过相关文章,不深入看,略过。
第 63 篇,《Concurrency In Go》的读书笔记,恰好我几个月前也写了一篇类似的读书笔记。不同的是,曹大这篇,代码样例为主,我的则以理解为主,代码样例则基本没有。
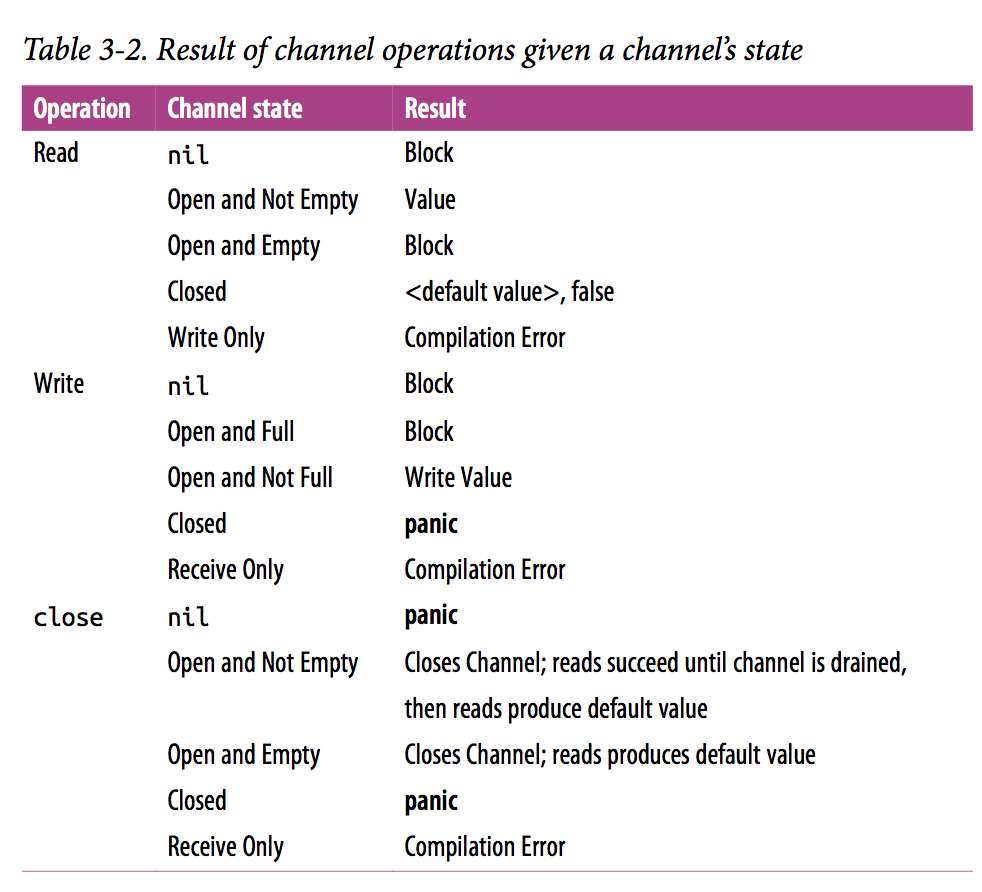
这有张操作 channel 的结果对照表,可以一用:
第 64 篇,timer 源码分析,不深入看。
第 65 篇,syscall 原理,以后需要的时候再来仔细研究。
第 66 篇,列举了一些英文书的出版社。如 O’Reilly,NoStarch,Manning,Apress,packt,最近我也看了 packt 出版社的《Distributed Computing With Go》,当然也是跟着曹大的书单读的。嗯,落后了 2 年。
第 67 篇,map 的源码分析,当初我写《深度解密 Go 语言之 map》时,参考了不少。
第 68 篇,select 源码分析。
第 69 篇,slice 源码分析。
第 70 篇,报告阶段性胜利,《Go 语言高级编程》初稿完成。曹大写的是关于 Go Web 的部分,字里行间可以看出他花了大力气进行总结:对于个人来说,通过这本书,把所有 web 领域相关的知识全部进行了梳理和总结(虽然有些还没有写)。可以比较自信地认为在 web 开发方面,本人已经没有任何方面的盲点和短板。要说问题,那可能也就是业务领域相关的问题了。
第 71 篇,业务遇到的问题,最终查到是 Go 语言自身的一个 bug:循环中的指针变量做 map 的 key 使用,会在 GC 时触发该 bug。在 1.9.2 上是必现的。
第 72 篇,sync 包源码分析,以后再看。
第 73 篇,semaphore 源码分析,以后再看。
2018 年的文章完了,这一年,曹大主攻 Go 语言,完成了 golang-notes,并且完成了《Go 语言高级编程》。
第 74 篇,《中台的末路》,去年在公众号“码农桃花源”上发出后,全网疯转,仅“码农桃花源”上就达到 7w+ 阅读,其他公众号、平台的阅读数就更不知多少了。
第 75 篇,又是列举了几个实际工作中碰到了案例,一个开源库对 sync.Pool 的使用,和实际场景中对开源的使用并没有发挥 sync.Pool 的作用,且在高并发场景下导致了锁竞争;第 2 个例子是 metrics 上报也会遇到锁竞争;第 3 个例子是打日志。得出结论:不可能通过看源码就能看出问题,早做压测保平安。
上面说的几个问题实际上本质都是并发场景下的 lock contention 问题,全局写锁是高并发场景下的性能杀手,一旦大量的 Goroutine 阻塞在写锁上,会导致系统的延迟飚升,直至接口超时。在开发系统时,涉及到 sync.Pool、单个 FD 的信息上报、以及写日志的场景时,应该多加注意。早做压测保平安。
第 76 篇,ghost 支持了mermaid。
第 77 篇,年终总结和年初计划。这里看到了曹大和欧神的互动,名场面。

第 78 篇,从功能上来讲,规则引擎的基本就是一个 bool 表达式的解析和求值过程。可以直接使用 Go 的内置 parser 库完成上面一个基本规则引擎的框架。
第 79 篇,主要内容应该是曹大之前竞选 Gopher China 讲师时准备的。又是根据实际业务系统的一次精彩总结,希望以后自己也能写这样的东西。即使不能公开,也能私下总结一下。
第 80 篇,流式计算中的分布式快照的算法介绍,看不太懂。主要内容是最早的一篇论文及之后 FaceBook 出的一篇新论文的介绍。
第 81 篇,从这篇开始,是一个序列专门讲微服务相关的内容,比较精彩。本文主要是说通用语言的问题,比如高层讲战略用的是中文,但底层程序员用的是英文,这中间有一个翻译导致的信息差。这在微服务上是很难解决的,例如对快车的翻译在不同的系统中叫法是不一样的。
上面提到的 fastcar 出现在我们系统提供给别人所用的 api 的关键字段中,quickcar 出现在我们内部数据库的字段名中,kuaiche 出现在异步发送的消息中。
但我的现公司其实用的是统一的一个 idl 库,可以解决很多问题。
第 82 篇,继续说微服务的问题,进行拆分之后,各个小模块理论上可以用最适合的语言去实现,但这就造成了技术栈不统一的一些毛病,例如同一个 client 需要用各种不同的语言来实现,当遇到组织架构变动的时候,接手都很麻烦。B 站是很早就统一了技术栈的。
第 83 篇,新增功能时,可能同时需要改很多模块,从设计原则上来讲,逻辑上相同或者类似的代码应该放在一个地方来实现。这个稍微学过一点 SOLID 中的 SRP 原则就应该知道。这样可以避免逻辑本身过于分散,好处是:“一个类(模块)只会因为一个理由而发生变化”,其实就是相同的需求,尽量能够控制在单模块内完成。但职场上很多人并不是这么考虑的,做这件事是否有收益是第一要务。
第 84 篇,业界有个名词叫 dependency hell,指的是软件系统因依赖过多,或依赖无法满足时会导致软件无法运行。服务之间的循环依赖也有很多。程序员在当前的微服务架构下,将持续地被外部的垃圾 SDK 和各种莫名其妙的依赖问题所困。
第 85 篇,拆分成微服务后,一致性是个大问题。大多数公司的架构师嘴里的最终一致,依靠的都是人肉而非技术。
第 86 篇,现实中总要考虑上“政治”因素,推动事情并不容易,尤其是跨部门的协作。
如果一个公司的组织架构已经基本成型了,那么基本上设计出的系统架构和其人员组织架构必然是一致的。
之前和同事一起得到了一个在大公司内推进事情的靠谱结论,如果一件事情在一个部门内就可以解决,那可以开开心心地推动它解决。如果一件事情需要跨部门,那还需要本部门的大领导出面才能解决,哪怕这事情再小。如果一件事情需要跨两个部门,那就没治了,谁出面都不行。这种事情做不了的。而如果一件事情和你要跨的部门 KPI 有冲突,那就更别想了,把部门重组了才能解决,这是 CTO 才能干的事情。
第 87 篇,一篇回答知乎上“有哪些优秀的 Go 面试题”的答案。当初第一次看文章的时候,很多不懂,现在看很多地方懂了。
第 88 篇和 89 篇是参与 tidb talent-plan 的题解。前者是一个 merge_sort,后者是 map-reduce。
第 90 篇,尝试对接入做到完全配置化,从 SQL 语句得到启发,通过定义的元组来描述外部的数据、内部的存储。其实我没太懂,以后再研究下。
第 91 篇,讲了 Go 1.13 在 defer 上的一些优化。主要在某些情况下,可以用 deferprocStack 来代替以前的从堆上分配资源,提升性能。
第 92 篇,探索一个案例代码的优化过程。起因是看到群里有人问的一个含有 dead code 的样例代码是如何优化的,然后使用 GOSSAFUNC=main go build com.go 看了下优化过程。结论是:优化是在编译器后端做的。关于后端的优化过程,这里有一个欧神开发的在线小工具,可以很方便的查看:https://golang.design/gossa。
从词法分析到语法分析一般被称为编译器的前端(frontend),而中间代码生成和目标代码生成则是编译器后端(backend)。
第 93 篇,某团圆节(应该是中秋节吧)线上发上的真实案例,不是事故:下游系统抖动了,超时,很多 g 挂在 gopark 上,没法复用;只能创建更多的 g,这些 g 会被 append 进 allgs 数组,在 sysmon/GC 等时机会扫描 allgs;即使下游恢复了,allgs 数组也不会收缩,使得 CPU 消耗变大。只能通过重启恢复。
第 94 篇,博客用 caddy2 上 https,看着导航栏左边的小绿锁,更开心了。
第 95 篇,一个小的程序代码,只用 Rlock 的时候竟然“发现”有锁冲突,不可思议,经过排查发现:大量的 g 调度下,在 g 的执行过程中如果有调用任意的会切换 g 调度的情况下,下次回到调度该 g 的时间无法保证。还是挺有意思的。
第 96 篇,依赖反转原则,在很多地方都被人用不同的名词说过。名词不同,但本质相同。
第 97 篇,讲 ACL 的一些问题,不太能 Get 到精髓。
第 98 篇,MQ 的数据生产方、消费方、MQ 的维护者,三方各怀鬼胎,真正关心 MQ 数据的只有整个消息流的末端团队,但他控制不了生产者。很多事故的发生都是因为生产者重构导致发出有问题的消息。本问提出了 2 种可能的数据检验方案。
2019 年的文章看完了。这一年,曹大比较关注工程领域,微服务方面有不少输出。另外,排查了很多线上 Go 相关的问题。上一年读完源码,这一年就大展身手了。
第 99 篇,2020 年第一篇,是一道知乎上的题目,有些地方可能还会拿来做面试题,但其实只要运行一下就知道答案。再看看逃逸分析、SSA 优化就可以知道为什么了。文章最后一句,送给面试官:要是哪位工程师拿这个去做面试题,那就太缺德啦!
第 100 篇,线上的一个 panic case,偶现。最终排查的原因是 waitgroup 使用不当,造成并发读写 map,程序崩溃。文章里写一开始系统负责人声称一定是离职员工的锅,连代码都不愿意看。但曹大三下五除二,就还原了事实真相。
第 101 篇,举了一个打日志也可能造成锁竞争的例子,原因是最后都会加锁:fd.writeLock()。
如果提前有一些预见性,做好针对性压测,那就不会让你的用户在关键时刻靠重启续命了。
第 102 篇,主要讲了切片截取会导致内存泄露,并给出了相关的例子。
第 103 篇,《工程师应该怎么学习》,推荐所有的技术人都看看,我前前后后看了很多遍。据说是曹大跑路的时候发到内网上的。写得很赞,看书、看英文书、看博客、读论文、实践、总结、写博客、独立思考、代码库、笔记库、演讲能力,哪一个都值得我们认真学习、实战。
你所要做的是提前做好准备,在那一天到来的时候,在聚光灯下旁征博引,谈笑风生。
第 104 篇,内行的吐槽更为致命。因转到蚂蚁搞 mosn,这里就是过程中遇到的 go mod 的依赖问题,最后通过 replace 解决。
第 105 篇,因为 Go 错误处理的原因,提高 Go 项目的测试覆盖率其实比较难。
第 106 篇,又是一篇犀利的吐槽。架构师不常见,天下系统都一样。言必谈 DDD,中台,战略,一到了落地环节提不出合理的见解和建议。对于个人来说,脚踏实地,打好基础,从解决实际问题开始。
第 107 篇,首先用压测工具 wrk fasthttp,标准库,rust 写的 hello 程序,发现 fasthttp 几乎和 rust 一样快。fasthttp 快的原因:goroutine workerpool,对创建的 goroutine 进行了重用;在整个 serve 流程中,几乎所有对象全部都进行了重用。当然,因为 ctx 的重用,某些场景下会掉坑。
第 108 篇,介绍了一些 golang linter,以及怎么集成到代码 CR 的流程中。
所以如果你在维护有节操的开源项目的话,可以考虑给你的项目加个 github action 了,试用下来,感觉 reviewdog 是最简单直观的。
第 109 篇,分析了一些常见组件的连接池的具体实现。包括:http 标准库、http2、fasthttp、gRPC、thrift、redigo、go-redis/redis、database/sql。
第 110 篇,Go context 的源码实现分析。
第 111 篇,Go 如何实现自动抓取 profile,快速定位问题。这篇介绍了实现原理。
第 112 篇,如何 patch 私有函数,原理+代码实现,非常过瘾。主要原理就是找到原私有函数的代码位置,将前面的数个字节用一段跳转指令覆盖,这样就能实现“劫持”,跳转到目标函数。真牛逼。
在 mac 上跑的时候,函数名有一小点不同,修改如下:
1func main() {
2 m := generateFuncName2PtrDict()
3
4 heiheiPrivate()
5 origin := replaceFunction(m["main.heiheiPrivate"], (uintptr)(getPtr(reflect.ValueOf(Replace))))
6 heiheiPrivate()
7 copyToLocation(m["main.heiheiPrivate"], origin)
8 heiheiPrivate()
9}
在“劫持”完之后,再“恢复现场”,再次调用 heiheiPrivate(),又恢复原样。妙啊!
第 113 篇,介绍了 LockOSThread 的奇技淫巧,它可以“杀”死线程:在退出的时候和当前 g 绑定的线程就会直接销毁。
第 114 篇,曹大看的 youtube 上的一个吐槽微服务的视频的总结笔记,很有曹大的风格,花式吐槽。
第 115 篇,自动 dump 的实现及样例说明。这是 mosn 上的一个开源项目,有了这个项目,绩效稳了。
第 116 篇,一篇 2013 年 Google 对 packetdrill 的论文翻译。看不太懂,先跳过,以后有用到的时候再来看。
第 117 篇,介绍了一个 Google 的 subset 算法解决微服务场景下连接数量的问题。
第 118 篇,详细解释 Go 1.14 中 defer 的优化。
| 序号 | 时间 | 题目 | 内容 |
|---|---|---|---|
| 1 | 2015-10-13 | 从零搭建 lnmp 环境 | 介绍如何使用 vagrant 搭建开发 lnmp 环境 |
| 2 | 2015-11-01 | 一致性哈希详解 | 介绍一致性哈希原理 |
| 3 | 2015-11-05 | Solr 5.3.1索引MySQL数据配置流程 | 一篇实战教程 |
| 4 | 2015-11-13 | Elasticsearch环境搭建和river数据导入 | 一篇实战教程,把 Solr 换成 ES 2.0 了 |
| 5 | 2015-11-15 | 漫谈服务化、微服务(一) | PHP 怎么做服务间调用 |
| 6 | 2015-11-16 | Elasticsearch环境搭建和river数据导入(二) | 接着第 4 篇,如何解决导入大表数据时虚拟机卡住的问题 |
| 7 | 2020-11-28 | 关于乐观锁 | 乐观锁,是一种写入、更新数据库时的逻辑特性 |
| 8 | 2020-11-30 | [译]Redis事务详解 | 官方 Transactions 小节的文档翻译 |
| 9 | 2016-01-10 | Elasticsearch环境搭建和river数据导入(三) | 因为 MySQL 主从延迟导致的丢数据问题的解决 |
| 10 | 2016-02-01 | 一致性哈希-虚拟结点生成 | 介绍了 groupcache 和 memcached 如何生成虚拟节点 |
| 11 | 2016-03-05 | elasticsearch服务开发总结 | 开发过程中遇到的问题及解决 |
| 12 | 2016-03-09 | Elasticsearch环境搭建和river数据导入(四) | 估计是 ES 最后一篇总结了 |
| 13 | 2016-04-11 | 中间件与责任链模式 | laravel 框架里的一个实现 |
| 14 | 2016-06-26 | beanstalkd 源码剖析 | 一个用 C 写的消息队列源码分析 |
| 15 | 2016-08-09 | 关于灰度发布 | 灰度发布的一些概念和实践 |
| 16 | 2016-08-10 | 谈一谈es的优势和限制 | 从数据库、检索服务、日志三个方面来谈 ES 能做的事,以及优势和限制 |
| 17 | 2016-08-28 | 使用sql来查询es | 开发了一个 elasticsql 项目,可以用 SQL 来查 ES |
| 18 | 2016-10-14 | 关于迅雷 | 简要介绍迅雷下载的原理 |
| 19 | 2016-10-23 | 初级程序员常犯错误一览 | 列举“初级”程序员的做法,共勉~ |
| 20 | 2016-11-06 | es stack升级5.0了 | 把 logstash/kibana/elasticsearch 之类的东西统统变成 5.0 |
| 21 | 2016-11-12 | 关于我们每天都在用的token | 公司登陆验证用的 Google Authenticator 来做校验的原理 |
| 22 | 2016-12-09 | 后端程序员面试题 | 翻译的一个后 GitHub 上的后端面试项目,并给出一些问题的回答 |
| 23 | 2016-12-16 | 重新探讨middleware | Go web 中间件如何写 |
| 24 | 2016-12-22 | 一次kafka 0.9的重复消费问题排查 | 仅通过读文档将发现了问题 |
| 25 | 2016-12-25 | 如何与低水平web开发联调 | 吐槽和低水平前端联调的事,并给出了应付的办法 |
| 26 | 2016-12-26 | sds与二进制安全 | redis set 命令是否是二进制安全的实验 |
| 27 | 2017-01-24 | [译]redis通信协议 | 一篇 redis client 和 server 的通信协议 |
| 28 | 2017-02-19 | 周末 | 听 B 站分享的一个总结 |
| 29 | 2017-03-11 | [译]Kafka Replication | 一篇 Kafka 消息 Replication 的原理的译文 |
| 30 | 2017-03-30 | 业务系统错误设计 | 从用户和研发的角度,来看业务系统如何处理错误的一些思考 |
| 31 | 2017-04-25 | 关于go的包管理 | Go 包管理的一些问题,这时还是 GOPATH |
| 32 | 2017-04-27 | 分布式锁 | 从 MySQL 到 redis 再到 redlock |
| 33 | 2017-05-10 | golang 和 ast | 直接用源码展示如何用 parser 生成 ast,以及实际应用 |
| 34 | 2017-05-20 | 从 information_schema 到自动生成的 web dao | 利用 information_schema 自动生成代码 |
| 35 | 2017-05-24 | 如何使你的 golang 项目达到 awesome go 的入选标准 | 关注两点:goreport、测试覆盖率(coveralls,或者 gocover) |
| 36 | 2017-06-20 | 关于 ofo | 关于 ofo 密码锁的一些方案设计 |
| 37 | 2017-07-11 | pprof 和火焰图 | 一篇实例教程 |
| 38 | 2017-06-21 | 企业级应用与屎一样的代码 | 公司级的代码质量问题及一些解决办法 |
| 39 | 2017-08-31 | 如何定位 golang 进程 hang 死的 bug | 如何定位 Go 的协作式调度的一个 bug |
| 40 | 2017-09-12 | 十周年 | 回顾本科、工作 |
| 41 | 2017-10-11 | 从求交集开始 | 求交集的一个计法 |
| 42 | 2017-10-28 | ApsaraCache 源码 diff 分析 | 分析优化如何实现 |
| 43 | 2017-11-30 | recover 并不是无懈可击的 | 有些情况下加 recover 也没用,例如并发 map 读写 |
| 44 | 2017-12-28 | clean architecture(上) | 《Clean Architecture》读书笔记 1 |
| 45 | 2017-12-30 | clean architecture(下) | 《Clean Architecture》读书笔记 2 |
| 46 | 2018-01-07 | 开源书 | 宣告一下,《Go 语言》高级编程还在搞,而且会搞完 |
| 47 | 2018-01-22 | 你的负载均衡真的均衡么? | 实验+推理说明一个均衡算法并不均衡 |
| 48 | 2018-01-31 | 使用 debugger 学习 golang | lldb 和 dlv 的功能和使用 |
| 49 | 2018-02-09 | 如何在 kv 系统中支持简单的 SQL | 对在线特征系统的接口的思考 |
| 50 | 2018-03-08 | [译]go 和 plan9 汇编 | 一篇 Go 汇编的翻译 |
| 51 | 2018-03-30 | 协作/非协作式抢占 | 宏观上描述两者的运行过程 |
| 52 | 2018-04-05 | Go 系列文章1:Channel 从使用到源码分析 | channel 的使用及源码分析 |
| 53 | 2018-04-08 | Go 系列文章2:Go 程序的启动流程 | Go 程序启动流程 |
| 54 | 2018-04-14 | [译]Go 和 interface 探究 | interface 如何组装等等 |
| 55 | 2018-04-22 | Go 系列文章3 :plan9 汇编入门 | Go 汇编相关,非常好 |
| 56 | 2018-05-01 | 分布式系统中的不可靠复制问题 | 业务指标如何收集、计算 |
| 57 | 2018-05-17 | goroutine 的状态切换 | 整理的 G 和 P 的状态切换图 |
| 58 | 2018-06-09 | 事故驱动开发 | 过于真实的互联网开发指南 |
| 59 | 2018-06-09 | blog 升级了。。 | 喜大普奔,博客升级 |
| 60 | 2018-06-09 | livelock | 《Concurrency In Go》里的一个活锁的例子 |
| 61 | 2018-06-10 | 2018 年的几个目标 | 年终总结 |
| 62 | 2018-06-17 | Go 系列文章4 : 调度器 | 源码分析 |
| 63 | 2018-06-18 | concurrency in go 读书笔记 | 记录的一些代码样例 |
| 64 | 2018-06-23 | Go 系列文章5 : 定时器 | timer 源码分析 |
| 65 | 2018-06-28 | Go 系列文章6: syscall | syscall 原理 |
| 66 | 2018-07-04 | packt 出版的书吐槽 | 一些英文书的出版社 |
| 67 | 2018-07-07 | Go 系列文章 7: map | map 源码分析 |
| 68 | 2018-07-16 | Go 系列文章 8: select | select 源码分析 |
| 69 | 2018-08-31 | Go 系列文章 9: slice | slice 源码分析 |
| 70 | 2018-09-01 | 松一口气 | 《Go 语言高级编程》初稿完成 |
| 71 | 2018-09-17 | Go 1.9.2 的 bug | Go 语言自身的一个 bug 复现 |
| 72 | 2018-10-04 | Go 系列文章 10: sync | sync 包源码分析 |
| 73 | 2018-11-24 | Go 系列文章 11: semaphore | semaphore 源码分析 |
| 74 | 2019-01-01 | 中台的末路 | 中台的困境 |
| 75 | 2019-01-06 | 几个 Go 系统可能遇到的锁问题 | 几个锁相关的案例 |
| 76 | 2019-01-24 | 在 ghost 中支持 mermaid | 博客的优化 |
| 77 | 2019-02-06 | 2018 总结 && 2019 目标 | 年终总结和年初计划 |
| 78 | 2019-02-08 | 基于 Go 的内置 Parser 打造轻量级规则引擎 | 使用 parser 可以实现一套规则引擎 |
| 79 | 2019-04-13 | 一套实时特征系统的迭代过程 | 真实的业务场景的迭代升级过程,非常精彩 |
| 80 | 2019-04-14 | 流式计算中的分布式快照 | 最早的一篇论文及之后 FaceBook 出的一篇新论文的介绍 |
| 81 | 2019-05-01 | 微服务的灾难-通用语言 | 通用语言的问题,很难重构解决 |
| 82 | 2019-05-01 | 微服务的灾难-技术栈 | 技术栈不统一也是有问题的 |
| 83 | 2019-05-02 | 微服务的灾难-拆分 | 依赖设计原则划分责任是不太可能的 |
| 84 | 2019-05-02 | 微服务的灾难-依赖地狱 | 依赖过多、多重依赖、依赖冲突、依赖循环 |
| 85 | 2019-05-03 | 微服务的灾难-最终一致 | 人肉最终一致 |
| 86 | 2019-05-03 | 微服务的灾难-康威定律和 KPI 冲突 | 除了组织架构的问题,还需要考虑 KPI 的问题 |
| 87 | 2019-05-11 | 一些问题的答案 | 一篇知乎回答 |
| 88 | 2019-05-11 | talent-plan tidb 部分个人题解-week 1 | tidb 题解 1 |
| 89 | 2019-05-11 | talent-plan tidb 部分个人题解-week 2 | tidb 题解 2 |
| 90 | 2019-08-31 | 一劳永逸接入所有下游数据系统 | 接入做到完全配置化 |
| 91 | 2019-09-04 | Go 1.13 defer 的变化 | 用 deferprocStack 提升性能 |
| 92 | 2019-09-22 | 查看 Go 的代码优化过程 | 探索一个样例代码的优化过程 |
| 93 | 2019-09-22 | 为什么 Go 模块在下游服务抖动恢复后,CPU 占用无法恢复 | 线上发生的真实案例 |
| 94 | 2019-10-04 | 从 nginx 切换到 caddy | 博客系统用 caddy2 上 https |
| 95 | 2019-10-13 | 一个和 RLock 有关的小故事 | 如何用 trace 查案 |
| 96 | 2019-10-20 | 依赖反转相关 | 很多不同的概念,但本质是一个东西 |
| 97 | 2019-11-02 | ACL 和俄罗斯套娃 | ACL 的一些问题 |
| 98 | 2019-11-24 | MQ 正在变成臭水沟 | MQ 的问题以及提出数据检验方案 |
| 99 | 2020-01-06 | 一个空 struct 的“坑” | 如何看穿一些弱智面试题 |
| 100 | 2020-01-09 | map 并发崩溃一例 | waitgroup 使用不当造成的并发读写 context,导致 panic |
| 101 | 2020-01-13 | 生于非阻塞,死于日志 | 写日志也可能会导致锁竞争 |
| 102 | 2020-01-19 | slice 类型内存泄露的逻辑 | 切片截取会导致内存泄露 |
| 103 | 2020-01-26 | 工程师应该怎么学习 | 终生学习,成为更好的自己 |
| 104 | 2020-04-19 | go mod 的智障版本选择 | Go mod 的问题 |
| 105 | 2020-05-01 | 为什么提升 Go 项目的测试覆盖率有点难 | 因为 Go 的错误处理 |
| 106 | 2020-06-06 | 架构的腐化是必然的 | 业务驱动下,能上升的不是系统做的好的,而是堆业务的 |
| 107 | 2020-06-14 | fasthttp 快在哪里 | fasthttp 快的原因是几乎所有对象全部都进行了重用 |
| 108 | 2020-07-06 | reviewdog | 如何在提 RP 的时候,检测代码质量 |
| 109 | 2020-07-11 | 一些连接池相关的总结 | 常用组件的连接池实现 |
| 110 | 2020-07-11 | Go context | Go context 源码分析 |
| 111 | 2020-08-13 | 无人值守的自动 dump(一) | 自动抓取 profile |
| 112 | 2020-09-04 | 在 Go 语言中 Patch 非导出函数 | 如何 patch 私有函数,原理加代码实现 |
| 113 | 2020-09-18 | 极端情况下收缩 Go 的线程数 | LockOSThread 的奇技淫巧 |
| 114 | 2020-10-06 | 10 个让微服务完全失败的 tips | 老外的一个演讲,花式吐槽微服务 |
| 115 | 2020-11-03 | 无人值守的自动 dump(二) | 书接第 111 篇,自动 dump 的实现及说明 |
| 116 | 2020-11-04 | packetdrill 简介 | 论文翻译 |
| 117 | 2020-11-28 | 用 subsetting 限制连接池中的连接数量 | 介绍的一个 Google 的算法 subsetting |
| 118 | 2020-12-03 | open coded defer 是怎么实现的 | Go 1.14 对 defer 的优化 |
术语
KVM:Kernel-based Virtual Machine is a virtualization module in the Linux kernel that allows the kernel to function as a hypervisor.
Consistent hashing:consistent hashing is a special kind of hashing such that when a hash table is resized, only n/m keys need to be remapped on average where n is the number of keys and m is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation.
二八原则:网站开发有一个比较著名的二八原则,就是 80% 的用户其实访问的都是 20% 的数据。所以实际上你只要把这 20% 的数据缓存好,就可以让网站整体的响应和吞吐量上一个等级。
Solr:Solr is an open-source enterprise-search platform, written in Java, from the Apache Lucene project. Its major features include full-text search, hit highlighting, faceted search, real-time indexing, dynamic clustering, database integration, NoSQL features and rich document handling.
- 原文作者:饶全成
- 原文链接:https://qcrao.com/post/blogs-written-by-xargin/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
