事故现场之依赖了不该依赖的 host ip
昨天,组里服务遇到了一个诡异的问题,跟着看了下原因,记录在此。
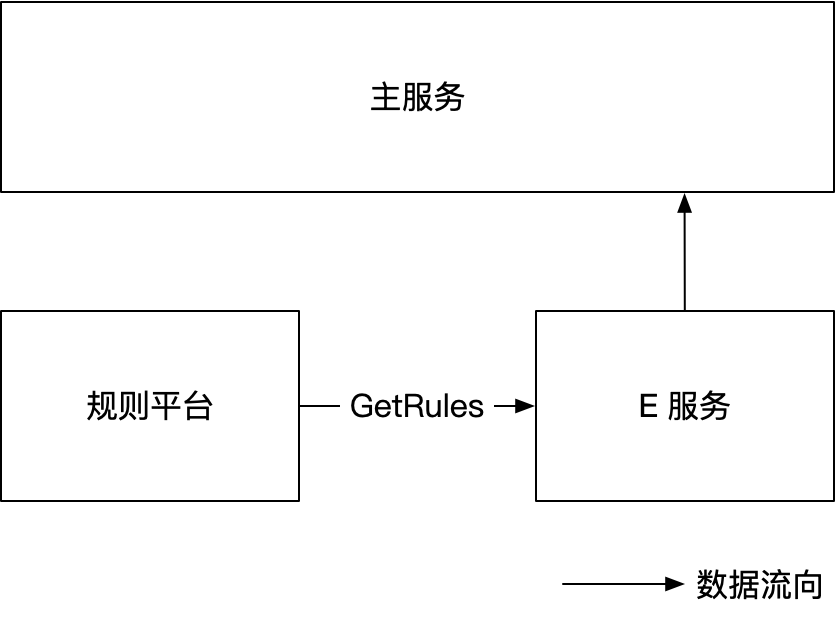
先介绍背景:我们维护了两个服务,一个对外服务,承接流量,称之为主服务,主服务会调用各种第三方 RPC 服务,获取各种字段,拼在一个大的 model 上。其中有一个 RPC 服务,称之为 E 服务,是我们自己维护的,它返回一部分字段。
E 服务会定时读取规则平台上的规则数据,根据这些规则计算返回给主服务的数据。运营或产品在规则平台上配置新的规则,通过审核后,E 服务会读取到新的规则,并应用到计算中,从而生成新的数据。
再将视角放大一些,我们的服务实际是整个链路上的一环,每次有新业务需求的时候,上下游还有各种服务需要变更,业务上线需要经过测试、联调、小流量、上线等阶段。
通常有新业务需求的时候,我们这部分只需要变更配置,在规则平台上操作就行了。主服务和 E 服务均是只读服务,为了测试方便,E 服务部了两个集群:default 集群(用于服务线上流量)、test 集群(用于线上测试)。QA 以及上下游可以调 test 集群的接口进行线上测试(当然这之前会经过线下环境测试)。
因此,只需要将新增的规则加载到 test 集群用于测试,但不加载到 default 集群影响线上流量。

规则平台提供 GetRules 接口返回全量规则数据。每个规则实际上可能有两个版本(切片含 2 个元素):小流量、全流量。规则上还有一个字段表示生效范围,对于小流量而言,表示哪些 ip 生效。当小流量验证没问题并推全量后,这个规则就只有一个版本了(切片只有一个元素)。

首次配置新规则时,先推小流量,配置项里需要填生效的 ip 列表。审核通过后,所有调用 GetRules 接口的 E 服务实例都能拿到新规则,但只有特定 ip 的实例才会使用新规则生成数据,这个 ip 就是之前配置规则 时填的。
只有机器 ip 和配置的小流量 ip 一致,才会使用小流量规则,否则就用全量规则。如果这个规则是第一次上,没有全量版本,那相当于这条规则不可见。对那些已经全量了的规则,需要有一些小的改动,就会先推小流量,这些规则就会包含两个版本。
为了方便测试,test 集群默认使用小流量规则。也就是说每次只要规则有变更,test 集群都能感知到,即它不受小流量 ip 的限制。
经历完线下测试、线上 test 集群测试等环节后,将小流量生效范围改成线上 default 集群的某个实例的 ip。这时只有这个实例能感知到新规则,等到验证、观察一段时间后,再推全量。这个新业务需求就全量平稳上线了。
背景就介绍到这里,本次事故的主人公,host ip 其实已经登场了。接着就来详细说说事故经过及原因。
前天有新业务需求过来,我们在规则平台上配置了一个新的规则,小流量配置了一台 test 集群的实例 ip 作为生效范围。这里实际上任意配置一个 ip 即可,因为 test 集群不看这个 ip,直接加载新规则。使用文档上说的是任意 ip 即可,但配置规则的同学为了“保险”,配上了 test 集群某台实例的 ip,自然也没问题(本来说的就是任意 ip 嘛),并且会“认为”更“保险”。
配置完成后,test 集群有 panic 发生,这个 panic 和新规则是有关的,只有加载了新规则后才会导致 panic 的发生。因此修复了一版代码,并且上线了 test 集群。
昨天中午收到主服务的业务方反馈,模型的某些关键字段有缺失。这些字段是调 E 服务获取的,因此排查 E 服务。再看字段开始缺失的时间和前一天上线 test 集群的时间是吻合的。但诡异的是,我们线上 default 集群并没有加载新规则,并且我们因为 panic 也只上线了 test 集群,为什么会影响线上流量呢?
非常诡异。
接着我们查到线上 default 集群也有 panic(报警失效了,这里待查),但这个 panic 只有在加载了新规则之后才会发生。问题是我们并没有让 default 集群加载新规则啊?
不对,这个 default 集群实例的 host ip 怎么和之前配置的小流量 ip 是一样的?这个 ip 是 test 集群的某台实例的。
再看 default 集群的这个实例启动时间和我们上线 test 集群的时间是吻合的,并且有先后关系,看起来是因果关系:上线 test 集群,导致 default 集群的某个实例发生了迁移,并且迁移到了某台物理机上,而这个物理机的 ip 正是之前配置的小流量 ip。
于是,“因果” 关系就出来了:上线 test 集群,导致 default 集群的某个实例被调度到之前 test 集群某个实例所在的 host 上。现在 default 集群的这个实例的 host ip 就在新规则的小流量范围内,因此加载新规则。然而新规则会导致 panic,但修复 panic 的变更只上线了 test 集群,因此 default 集群的某台实例会 panic,进而导致它返回的数据缺失某些字段。
问题的原因查到了,但同时也很费解:不同集群的实例所在的 host ip 能一样吗?为什么上线 test 集群,会引起 default 集群的实例发生调度?
在咨询了 Oncall 之后,我们才知道:
正常的维护,集群内机器负载的变化,都会造成实例的重新调度。
继续追问:
如果是一般的机器负载变化什么的引起的重新调度是容易理解的。但这个 case 诡异的地方在于:我升级了一个 test 集群的实例 a(它在 host1 上),升级完成的同时,default 集群的一个实例被迁移到了 host1 上。而且,这明显是有“因果”关系(从时间上来看)的。现在想知道这个因果关系是有可能的吗?如果是,能查到具体的因 -> 果吗?
Oncall 继续追查,发现这个所谓的因果关系并不成立,前后相隔了 2 分钟。可能是实例 b 所在的机器负载比较高,而 a 实例所在的机器因为 a 刚被调度走,负载下来了,实例 b 有更优的调度选择,就恰好被调度到 host1 上了。
进一步追问得知,不同集群的实例 ip 是有可能相同的。因为 test/default 集群是两个业务集群,它们实际在同一个物理集群上,所以它们的实例有可能被调度到同一个 host。
如果我们新建了两个业务集群(同一个物理集群),目的是进行隔离。既然不同集群的实例可能会被分配到同一台机器上,那还能起到隔离的作用吗?
可以。首先,流量调度会根据业务集群进行,基本就能进行隔离了。并且,一般情况下,实例都是有资源限制的,不太可能会让其他实例受影响。
总之,事故的原因是我们依赖了不该依赖的 host ip。想到的解决办法有 2 点:
- 在 test 集群测试时,小流量 ip 随便给一个无效的值,例如:127.0.0.1。这样,default 集群就不可能加载到小流量的新规则了。缺点是当 default 集群小流量的时候,设置的 ip 上可能有多个实例,小流量变成了中流量。
- 将小流量 ip 改成使用 pod-name。缺点是这个实例可能会被突然调度走,无法进行小流量测试了。
小流量 ip 这个不起眼的地方,竟然会引起事故。根本原因是我们在容器环境下,还依赖了 ip,这是有问题的。并且实例调度时机有哪些、不同集群的实例 ip 会不会相同,这些我们之前并没有弄清楚。
延伸一下,我们不该依赖任何没有弄清原理的东西。
- 原文作者:饶全成
- 原文链接:https://qcrao.com/post/error-depend-on-host-ip/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
