曹大带我学 Go(8)—— 一个 metrics 打点引发的事故
最近线上事故频发,搞得焦头烂额,但是能用上跟曹大学的知识并定位出了问题,还是值得高兴一把的。毕竟“打破砂锅问到底”,“定位出根因”一直是技术人的优良品质。
虽然我们总是逃不过事故驱动开发的魔咒,但吃一堑长一智,看别人的事故,学到的是自己的能力。
现象
一个平凡的午高峰,服务在全量上线的过程中,碰到一个非常重要的下游接口超时(后来发现该下游也在上线,可用实例数变少,正常实例负载变高,超时了一丢丢),拿不到该拿的数据,阻塞了启动。这样,打到线上正常实例上的流量就增加了。
不大会儿,线上大量实例 OOM,报警满天飞。不得已,回滚(遇到事故,第一件事就是回滚)。没想到,回滚无效,OOM 的实例数还是一直在增加,给跪了。
中间查到服务在启动过程中,一直在尝试调那个超时的下游,就临时把超时时间加大,并取消回滚,紧急上线了一把。
之后,正常启动的实例越来越多,服务逐渐恢复。
第一天排查
发生事故之后就是排查过程了。
第一天,只查到了 OOM 的实例 goroutine 数暴涨,接口 QPS 有尖峰,比正常翻了几倍。所以,得到的结论就是接口流量太多,超过服务极限,导致 OOM。
接着尝试在预览环境压测,没有复现 OOM,gg。
结论有问题!
第二天排查
第二天运气比较好,发现了线上有一个实例在不断地重启,一看监控,发现正常启动后,5 分钟左右就 OOM 了。
有现场就不慌。
正好跟着曹大学会了如何用 pprof 查问题,马上就安排,三下五除二就搞定了。
先看 inuse_space:
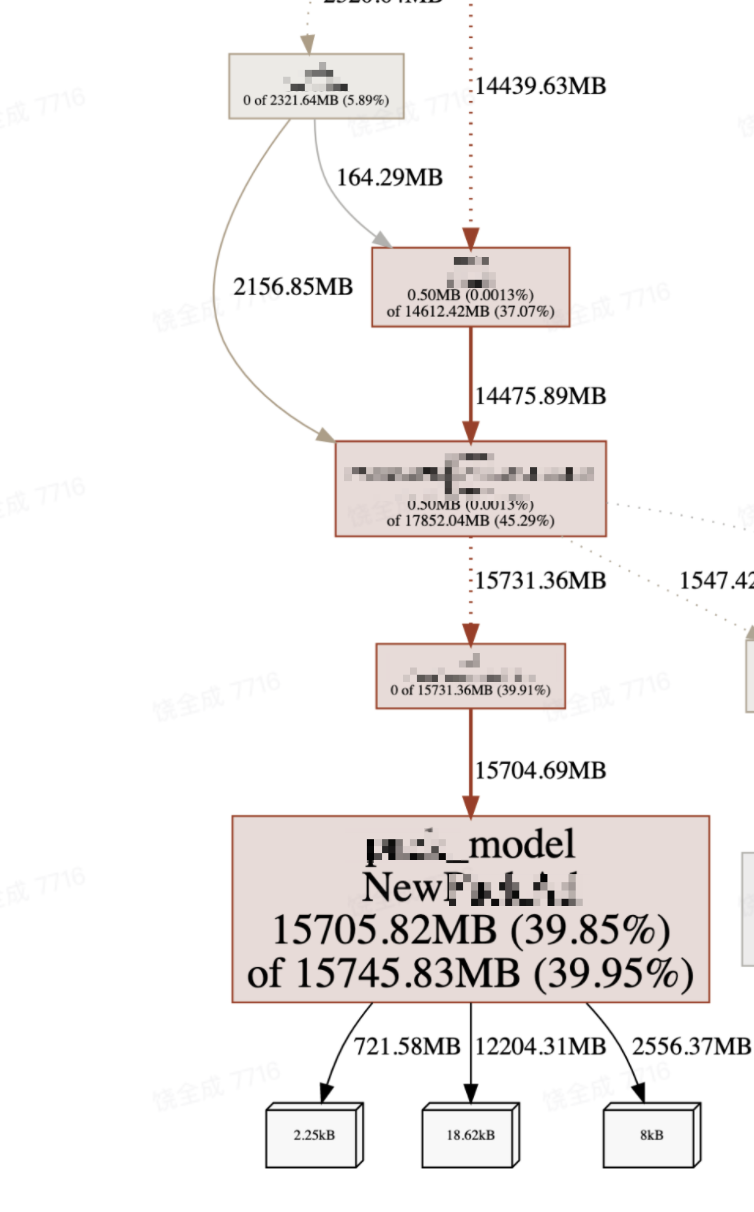
虽然,这个 model 占用的内存比较高,但这是正常的业务逻辑,看了看相关的代码最近也没有改动。
所以,这个只能是果,不是因。
再看 CPU:

中间加粗的红色线条和方框就差要告诉我有问题的代码在哪一行了!图上方有调 metrics 的函数名(这里没展示出来),一搜就搜出来了。
再看了下 goroutine:

结论还是一样的。
顺着图上的函数名,马上就在一个多重嵌套循环里找到了一处不那么显眼的打点。
metrics 打点的剧本我熟,之前看了曹大的“几个 Go 系统可能遇到的锁问题”的文章(点击阅读原文可读),逻辑大概是这样的:
由于
metrics底层是用 udp 发送的,有文件锁,大量打点的情况下,会引起激烈的锁冲突,造成 goroutine 堆积、请求堆积,和请求关联的 model 无法释放,于是就 OOM 了。
然后我们替换 bin 上到这台 OOM 的机器,果然恢复正常了,收工!
最后看了下 metrics 的代码,其实还不是文件锁的原因。不过也差不多了,也是一把大锁,所有 goroutine 的打点都会先 append 到一个 slice 里,append 前要先加锁。
由于这个地方的打点非常多,几十万 QPS,一冲突,goroutine 都 gopark 去等锁了,持有的内存无法释放,服务一会儿就 gg 了。
总结
引发这次事故的代码其实是一年多前写的,跑了一年都没出事,这次就遇到了,你说可气不?
幸亏不是自己写的,但也要敲个警钟:我写的每一行代码,将来都可能会引发事故,一定要认真对待。
遇到 OOM 不可怕,有现场就行。拿不到现场,我也没啥好办法。实在不行,用曹大的 holmes 试试,这个工具还是很厉害的,还帮曹大贡献了个 golang 的 mr。
平时要多看相关的事故排查文章,必要的时候练习一下 pprof 工具的使用,关键的时候还是能顶用的。
- 原文作者:饶全成
- 原文链接:https://qcrao.com/post/accident-by-a-metric/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
