曹大带我学 Go(11)—— 从 map 的 extra 字段谈起
熟悉 map 结构体的读者应该知道,hmap 由很多 bmap(bucket) 构成,每个 bmap 都保存了 8 个 key/value 对:
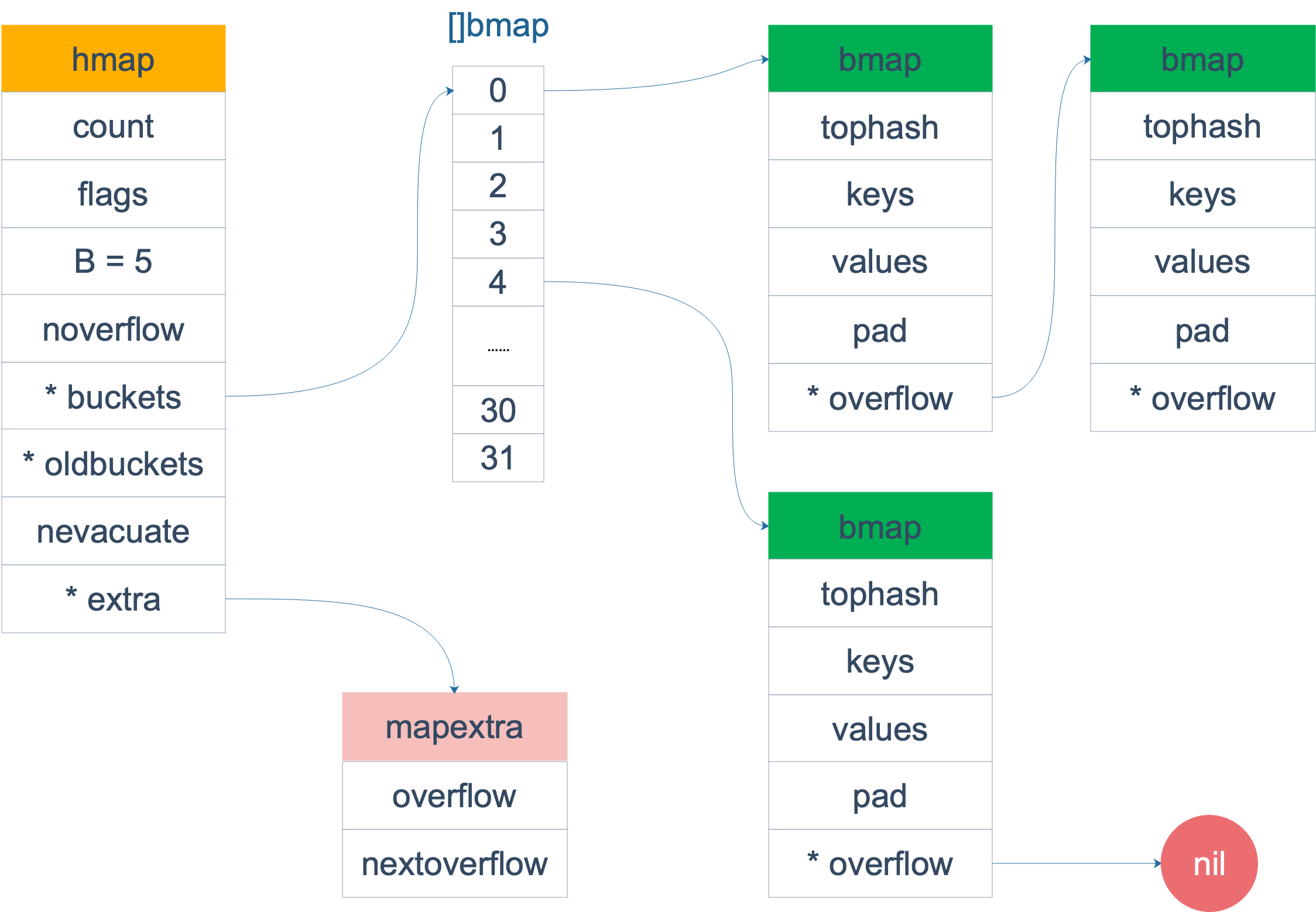
有时落在同一个 bmap 中的 key/value 太多了,超过了 8 个,就会由溢出 bmap 来承接,即 overflow bmap(后面我们叫它 bucket)。溢出的 bucket 和原来的 bucket 形成一个“拉链”。
对于这些 overflow 的 bucket,在 hmap 结构体和 bmap 结构体里分别有一个 extra.overflow 和 overflow 字段指向它们。
如果我们仔细看 mapextra 结构体里对 overflow 字段的注释,会发现这里有“文章”。
其中 overflow 这个字段上面有一大段注释,我们来看看前两行:
1// If both key and elem do not contain pointers and are inline, then we mark bucket
2// type as containing no pointers. This avoids scanning such maps.
意思是如果 map 的 key 和 value 都不包含指针的话,在 GC 期间就可以避免对它的扫描。在 map 非常大(几百万个 key)的场景下,能提升不少性能。
那具体是怎么实现“不扫描”的呢?
我们知道,bmap 这个结构体里有一个 overflow 指针,它指向溢出的 bucket。因为它是一个指针,所以 GC 的时候肯定要扫描它,也就要扫描所有的 bmap。
而当 map 的 key/value 都是非指针类型的话,扫描是可以避免的,直接标记整个 map 的颜色(三色标记法)就行了,不用去扫描每个 bmap 的 overflow 指针。
但是溢出的 bucket 总是可能存在的,这和 key/value 的类型无关。
于是就利用 hmap 里的 extra 结构体的 overflow 指针来 “hold” 这些 overflow 的 bucket,并把 bmap 结构体的 overflow 指针类型变成一个 unitptr 类型(这些是在编译期干的)。于是整个 bmap 就完全没有指针了,也就不会在 GC 期间被扫描。
1overflow *[]*bmap
另一方面,当 GC 在扫描 hmap 时,通过 extra.overflow 这条路径(指针)就可以将 overflow 的 bucket 正常标记成黑色,从而不会被 GC 错误地回收。
当我们知道上面这些原理后,就可以利用它来对一些场景进行性能优化:
map[string]int -> map[[12]byte]int
因为 string 底层有指针,所以当 string 作为 map 的 key 时,GC 阶段会扫描整个 map;而数组 [12]byte 是一个值类型,不会被 GC 扫描。
我们用两种方法来验证优化效果。
主动触发 GC
这里的测试代码来自文章《尽量不要在大 map 中保存指针》:
1func MapWithPointer() {
2 const N = 10000000
3 m := make(map[string]string)
4 for i := 0; i < N; i++ {
5 n := strconv.Itoa(i)
6 m[n] = n
7 }
8 now := time.Now()
9 runtime.GC()
10 fmt.Printf("With a map of strings, GC took: %s\n", time.Since(now))
11
12 // 引用一下防止被 GC 回收掉
13 _ = m["0"]
14}
15
16func MapWithoutPointer() {
17 const N = 10000000
18 m := make(map[int]int)
19 for i := 0; i < N; i++ {
20 str := strconv.Itoa(i)
21 // hash string to int
22 n, _ := strconv.Atoi(str)
23 m[n] = n
24 }
25 now := time.Now()
26 runtime.GC()
27 fmt.Printf("With a map of int, GC took: %s\n", time.Since(now))
28
29 _ = m[0]
30}
31
32func TestMapWithPointer(t *testing.T) {
33 MapWithPointer()
34}
35
36func TestMapWithoutPointer(t *testing.T) {
37 MapWithoutPointer()
38}
直接用了 2 个不同类型的 map:前者 key 和 value 都是 string 类型,后者 key 和 value 都是 int 类型。整个 map 大小为 1kw。
测试结果:
1=== RUN TestMapWithPointer
2With a map of strings, GC took: 150.078ms
3--- PASS: TestMapWithPointer (4.22s)
4=== RUN TestMapWithoutPointer
5With a map of int, GC took: 4.9581ms
6--- PASS: TestMapWithoutPointer (2.33s)
7PASS
于是验证了 string 相对于 int 这种值类型对 GC 的消耗更大。正如这篇文章的标题所说:
Go语言使用 map 时尽量不要在 big map 中保存指针。
用 pprof 看对象数
第二种方式就是直接开个 pprof 来看 heap profile。这次我们将 string 类型的 key 优化成数组类型:
1package main
2
3import (
4 "fmt"
5 "io"
6 "net/http"
7 _ "net/http/pprof"
8)
9
10// var m = map[[12]byte]int{}
11var m = map[string]int{}
12
13func init() {
14 for i := 0; i < 1000000; i++ {
15 // var arr [12]byte
16 // copy(arr[:], fmt.Sprint(i))
17 // m[arr] = i
18
19 m[fmt.Sprint(i)] = i
20 }
21}
22
23func sayHello(wr http.ResponseWriter, r *http.Request) {
24 io.WriteString(wr ,"hello")
25}
26
27func main() {
28 http.HandleFunc("/", sayHello)
29 err := http.ListenAndServe(":8000", nil)
30 if err != nil {
31 fmt.Println(err)
32 }
33}
注意,去掉代码里的注释即可将 key 从 string 优化成数组类型。
直接在 init 里构建 map,然后开 pprof 看 profile:


对象数从 33w 下降到 1.5w,效果非常明显。
map 的 key 和 value 要不要在 GC 里扫描,和类型是有关的。数组类型是个值类型,string 底层也是指针。
不过要注意,key/value 大于 128B 的时候,会退化成指针类型。
那么问题来了,什么是指针类型呢?**所有显式 *T 以及内部有 pointer 的对像都是指针类型。
——来自董神的 map 优化文章
关于超过 128 字节的情况,源码里也有说明:
1 // Maximum key or elem size to keep inline (instead of mallocing per element).
2 maxKeySize = 128
3 maxElemSize = 128
总结
当 map 的 key/value 是非指针类型时,GC 不会对所有的 bucket 进行扫描。如果线上服务使用了一个超大的 map ,会因此提升性能。
为了不让 overflow 的 bucket 被 GC 错误地回收掉,在 hmap 里用 extra.overflow 指针指向它,从而在三色标记里将其标记为黑色。
如果你用了 key 是 string 类型的 map,并且恰好这些 string 是定长的,那么就可以用 key 为数组类型的 map 来优化它。
通过主动调用 GC 以及开 pprof 都可观察优化效果。
- 原文作者:饶全成
- 原文链接:https://qcrao.com/post/talk-about-map-extra-field/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
